创建自定义环境#
本文档概述了创建新环境以及 Gymnasium 中包含的用于创建新环境的有用包装器、实用程序和测试。
设置#
推荐解决方案#
按照pipx文档安装
pipx。然后安装Copier:
pipx install copier
替代解决方案#
使用Pip或Conda安装Copier:
pip install copier
或者
conda install -c conda-forge copier
生成你的环境#
你可以通过运行以下命令来检查Copier是否已正确安装,该命令应输出一个版本号:
copier --version
然后,你可以运行以下命令,并将字符串path/to/directory替换为你希望创建新项目的目录的路径。
copier copy https://github.com/Farama-Foundation/gymnasium-env-template.git "path/to/directory"
回答问题后,完成后你应该得到如下的项目结构:
.
├── gymnasium_env
│ ├── envs
│ │ ├── grid_world.py
│ │ └── __init__.py
│ ├── __init__.py
│ └── wrappers
│ ├── clip_reward.py
│ ├── discrete_actions.py
│ ├── __init__.py
│ ├── reacher_weighted_reward.py
│ └── relative_position.py
├── LICENSE
├── pyproject.toml
└── README.md
继承 gymnasium.Env#
在学习如何创建自己的环境之前,你应该查看 Env。
为了说明继承 Env 的过程,我们将实现非常简单的游戏,称为 GridWorldEnv。我们将在 gymnasium_env/envs/grid_world.py 中编写自定义环境的代码。该环境由固定大小的二维方格网格组成(通过构造函数中的 size 参数指定)。每个时间步,代理可以在网格单元格之间垂直或水平移动。代理的目标是在每个时间步导航到网格上随机放置的目标。
观察提供了目标和代理的位置。
我们的环境中有4个动作,分别对应于“右”、“上”、“左”和“下”的移动。
一旦代理到达目标所在的网格单元格,就会发出完成信号。
奖励是二元稀疏的,意味着即时奖励总是零,除非代理到达目标,则为1。
在这个环境中(size=5),一个情节可能如下所示:
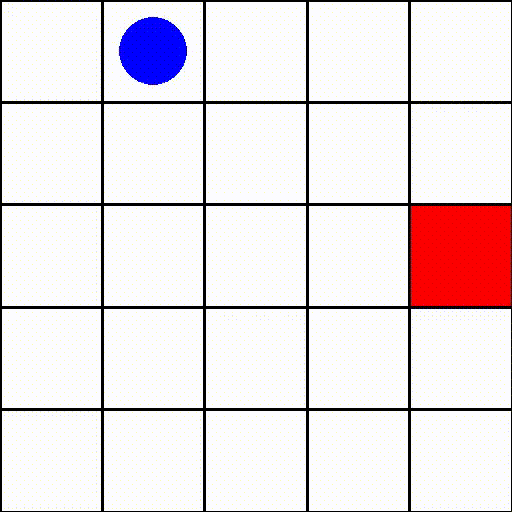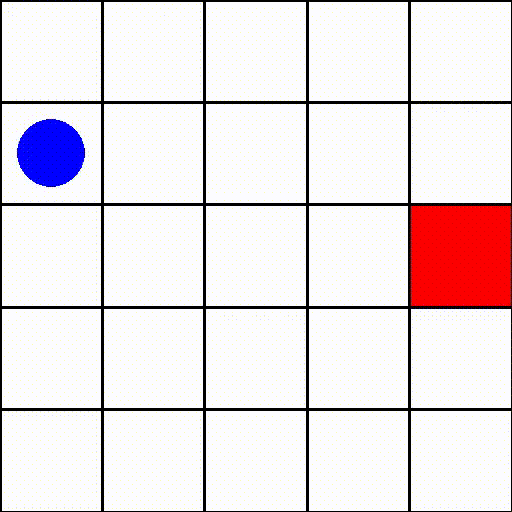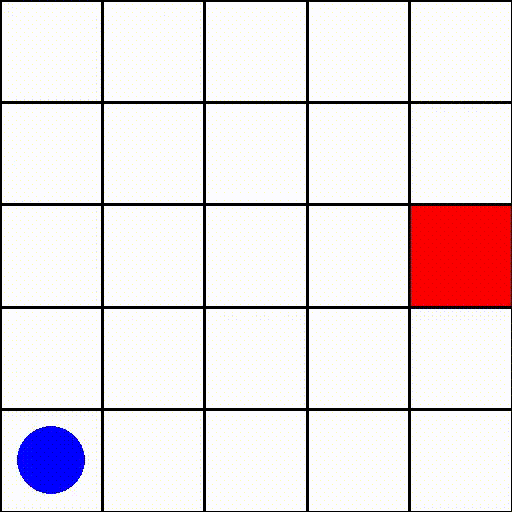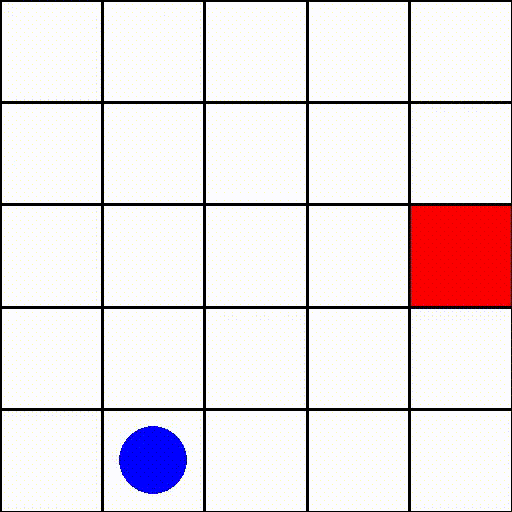
其中蓝色点代表代理,红色方块表示目标。
现在让我们逐步了解GridWorldEnv的源代码:
声明和初始化#
我们的自定义环境将继承自抽象类 Env。不要忘记在类中添加metadata属性。在那里,你应该指定你的环境所支持的渲染模式(例如,"human", "rgb_array", "ansi")以及你的环境应该以何种帧率进行渲染。每个环境都应该支持 None 作为渲染模式;你不需要在元数据中添加它。在 GridWorldEnv 中,支持“rgb_array”和“human”模式,并以4 FPS进行渲染,即 metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 4}。
我们环境的__init__方法将接受整数size,该参数决定了方格网格的大小。我们将设置一些用于渲染的变量,并定义self.observation_space和self.action_space。在我们的例子中,观察应该提供关于代理和目标在二维网格上的位置的信息。我们将选择使用带有键"agent"和"target"的字典形式来表示观察。一个观察可能看起来像是{"agent": array([1, 0]), "target": array([0, 3])}。由于我们的环境有4个动作(“右”、“上”、“左”、“下”),我们将使用Discrete(4)作为动作空间。下面是GridWorldEnv的声明和__init__的实现:
# gymnasium_env/envs/grid_world.py
from enum import Enum
import numpy as np
import pygame
import gymnasium as gym
from gymnasium import spaces
class Actions(Enum):
RIGHT = 0
UP = 1
LEFT = 2
DOWN = 3
class GridWorldEnv(gym.Env):
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 4}
def __init__(self, render_mode=None, size=5):
self.size = size # 方形网格的大小
self.window_size = 512 # PyGame 窗口大小
# 观测结果(Observations)是包含代理(agent)和目标(target)位置的字典。
# 每个位置编码为 {0, ..., `size`}^2 中的元素,即 MultiDiscrete([size, size])。
self.observation_space = spaces.Dict(
{
"agent": spaces.Box(0, size - 1, shape=(2,), dtype=int),
"target": spaces.Box(0, size - 1, shape=(2,), dtype=int),
}
)
self._agent_location = np.array([-1, -1], dtype=int)
self._target_location = np.array([-1, -1], dtype=int)
# We have 4 actions, corresponding to "right", "up", "left", "down"
# 有4个动作,分别对应“右”、“上”、“左”、“下”。
self.action_space = spaces.Discrete(4)
"""
以下字典将 `self.action_space` 中的抽象动作映射到如果采取该动作我们将走向的方向。
例如,0 对应“右”,1 对应“上”等。
"""
self._action_to_direction = {
Actions.RIGHT.value: np.array([1, 0]),
Actions.UP.value: np.array([0, 1]),
Actions.LEFT.value: np.array([-1, 0]),
Actions.DOWN.value: np.array([0, -1]),
}
assert render_mode is None or render_mode in self.metadata["render_modes"]
self.render_mode = render_mode
"""
如果使用人类渲染模式,`self.window` 将引用我们绘制的窗口。
`self.clock` 将是一个时钟,用于确保环境在人类模式下以正确的帧率渲染。它们将在首次使用人类模式之前保持为`None`。
"""
self.window = None
self.clock = None
pygame 2.6.1 (SDL 2.28.4, Python 3.12.2)
Hello from the pygame community. https://www.pygame.org/contribute.html
从环境状态构建观测器#
由于需要在 reset 和 step 中计算观测,使用(私有)方法 _get_obs很便利,它将环境的状态转换为观测。然而,这并不是强制性的,你也可以分别在 reset 和 step 中计算观察:
def _get_obs(self):
return {"agent": self._agent_location, "target": self._target_location}
也可以为 step 和 reset 返回的辅助信息实现类似的方法。在例子中,希望提供代理和目标之间的曼哈顿距离:
def _get_info(self):
return {
"distance": np.linalg.norm(
self._agent_location - self._target_location, ord=1
)
}
通常情况下,info 也会包含一些仅在step方法内可用的数据(例如,各个奖励项)。在这种情况下,我们需要在step中更新由_get_info返回的字典。
重置#
reset方法将被调用以启动新的情节。你可以假设在调用reset之前不会调用step方法。此外,每当发出完成信号时,都应该调用reset。用户可以传递seed关键字给reset来初始化环境使用的随机数生成器到一个确定的状态。建议使用由环境基类 Env 提供的随机数生成器self.np_random。如果你只使用这个RNG,你就不需要担心种子问题,但你需要记住调用super().reset(seed=seed)以确保 Env 正确地为RNG设置种子。一旦完成,我们可以随机设置环境的状态。在我们的例子中,我们随机选择代理的位置和随机样本目标位置,直到它们不与代理的位置重合。
reset方法应返回一个包含初始观察和一些辅助信息的元组。我们可以使用之前实现的_get_obs和_get_info方法来实现这一点:
def reset(self, seed=None, options=None):
# 需要以下行来为 self.np_random 设定种子
super().reset(seed=seed)
# 在代理的位置上均匀地随机选择
self._agent_location = self.np_random.integers(0, self.size, size=2, dtype=int)
# 随机抽样目标的位置,直到它不与代理的位置重合
self._target_location = self._agent_location
while np.array_equal(self._target_location, self._agent_location):
self._target_location = self.np_random.integers(
0, self.size, size=2, dtype=int
)
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, info
步骤#
step方法通常包含环境的大部分逻辑。它接受 action,计算应用该动作后的环境状态,并返回5元组(observation, reward, terminated, truncated, info)。参见:gymnasium.Env.step()。一旦计算了环境的新状态,我们可以检查它是否是一个终止状态,并相应地设置done。由于我们在GridWorldEnv中使用稀疏二进制奖励,一旦我们知道done,计算reward就变得简单了。为了收集observation和info,我们可以再次利用_get_obs和_get_info:
def step(self, action):
# Map the action (element of {0,1,2,3}) to the direction we walk in
direction = self._action_to_direction[action]
# We use `np.clip` to make sure we don't leave the grid
self._agent_location = np.clip(
self._agent_location + direction, 0, self.size - 1
)
# An episode is done iff the agent has reached the target
terminated = np.array_equal(self._agent_location, self._target_location)
reward = 1 if terminated else 0 # Binary sparse rewards
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, reward, terminated, False, info
渲染#
在这里,我们使用PyGame进行渲染。许多包含在Gymnasium中的环境也使用了类似的渲染方法,你可以将其作为自己环境的框架:
def render(self):
if self.render_mode == "rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode == "human":
pygame.init()
pygame.display.init()
self.window = pygame.display.set_mode(
(self.window_size, self.window_size)
)
if self.clock is None and self.render_mode == "human":
self.clock = pygame.time.Clock()
canvas = pygame.Surface((self.window_size, self.window_size))
canvas.fill((255, 255, 255))
pix_square_size = (
self.window_size / self.size
) # The size of a single grid square in pixels
# First we draw the target
pygame.draw.rect(
canvas,
(255, 0, 0),
pygame.Rect(
pix_square_size * self._target_location,
(pix_square_size, pix_square_size),
),
)
# Now we draw the agent
pygame.draw.circle(
canvas,
(0, 0, 255),
(self._agent_location + 0.5) * pix_square_size,
pix_square_size / 3,
)
# Finally, add some gridlines
for x in range(self.size + 1):
pygame.draw.line(
canvas,
0,
(0, pix_square_size * x),
(self.window_size, pix_square_size * x),
width=3,
)
pygame.draw.line(
canvas,
0,
(pix_square_size * x, 0),
(pix_square_size * x, self.window_size),
width=3,
)
if self.render_mode == "human":
# The following line copies our drawings from `canvas` to the visible window
self.window.blit(canvas, canvas.get_rect())
pygame.event.pump()
pygame.display.update()
# We need to ensure that human-rendering occurs at the predefined framerate.
# The following line will automatically add a delay to keep the framerate stable.
self.clock.tick(self.metadata["render_fps"])
else: # rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2)
)
关闭#
close方法应该关闭环境使用的任何打开的资源。在许多情况下,你实际上不需要费心去实现这个方法。然而,在我们的示例中,render_mode可能是"human",我们可能需要关闭已经打开的窗口:
def close(self):
if self.window is not None:
pygame.display.quit()
pygame.quit()
在其他环境中,close方法还可能关闭已打开的文件或释放其他资源。在调用了close之后,你不应该再与环境进行交互。
注册环境#
为了使自定义环境能够被Gymnasium检测到,它们必须按如下方式注册。我们将选择将此代码放在gymnasium_env/__init__.py中。
from gymnasium.envs.registration import register
register(
id="gymnasium_env/GridWorld-v0",
entry_point="gymnasium_env.envs:GridWorldEnv",
)
环境ID由三个部分组成,其中两个是可选的:一个可选的命名空间(这里是“gymnasium_env”)、一个必需的名称(这里是“GridWorld”)以及一个可选但推荐的版本(这里是v0)。它可能还注册为“GridWorld-v0”(推荐的方法)、“GridWorld”或“gymnasium_env/GridWorld”,然后在创建环境时使用适当的ID。
关键字参数“max_episode_steps=300”将确保通过“gymnasium.make”实例化的GridWorld环境将被包装在 “TimeLimit”包装器中(有关更多信息,请参阅 wrappers)。如果代理达到了目标或在当前情节中执行了300步,则会产生 done 信号。要区分截断和终止,您可以检查 info["TimeLimit.truncated"]。
除了id和entrypoint之外,您还可以向register传递以下额外的关键字参数:
名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
|
|
任务被认为是解决之前的奖励阈值 |
|
|
|
即使在种子化后,此环境是否为非确定性的 |
|
|
|
一个情节可以包含的最大步数。如果不是 |
|
|
|
是否将环境包装在 |
|
|
|
传递给环境类的默认 |
这些关键字(除了max_episode_steps、order_enforce和kwargs)不会改变环境实例的行为,而只是提供有关您的环境的额外信息。注册后,可以使用env = gymnasium.make('gymnasium_env/GridWorld-v0')创建自定义的GridWorldEnv环境。
gymnasium_env/envs/__init__.py应该包含:
from gymnasium_env.envs.grid_world import GridWorldEnv
如果您的环境没有注册,您可以选择传递一个模块来导入,该模块将在创建环境之前注册您的环境,如下所示 - env = gymnasium.make('module:Env-v0'),其中module包含注册代码。对于GridWorld环境,通过导入gymnasium_env来运行注册代码,因此如果无法显式导入gymnasium_env,您可以通过env = gymnasium.make('gymnasium_env:gymnasium_env/GridWorld-v0')在创建时进行注册。这在您只能将环境ID传递给第三方代码库(例如学习库)时特别有用。这使您能够在不编辑库源代码的情况下注册您的环境。
创建软件包#
最后一步是将我们的代码结构化为一个Python软件包。这涉及到配置pyproject.toml。如何做到这一点的最小示例如下:
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project]
name = "gymnasium_env"
version = "0.0.1"
dependencies = [
"gymnasium",
"pygame==2.1.3",
"pre-commit",
]
创建环境实例#
现在,您可以使用以下命令在本地安装您的软件包:
pip install -e .
然后,您可以通过以下方式创建一个环境的实例:
# run_gymnasium_env.py
import gymnasium
import gymnasium_env
env = gymnasium.make('gymnasium_env/GridWorld-v0')
您还可以将环境构造函数的关键字参数传递给gymnasium.make以自定义环境。在我们的例子中,我们可以这样做:
env = gymnasium.make('gymnasium_env/GridWorld-v0', size=10)
有时,您可能会发现跳过注册并直接调用环境构造函数更方便。有些人可能觉得这种方法更符合Python风格,而且像这样实例化的环境也完全可以(但请记住也要添加包装器!)。
使用包装器#
通常,我们希望使用不同版本的自定义环境,或者我们想要修改Gymnasium或其他方提供的环境的行为。包装器允许我们在不更改环境实现或添加任何样板代码的情况下实现这一点。有关如何使用包装器以及如何实现自己的包装器的详细信息,请参阅包装器文档。在我们的示例中,观察结果不能直接用于学习代码,因为它们是字典。然而,我们实际上不需要修改我们的环境实现就可以解决这个问题!我们只需在环境实例上添加一个包装器,将观察结果展平为单个数组:
import gymnasium
import gymnasium_env
from gymnasium.wrappers import FlattenObservation
env = gymnasium.make('gymnasium_env/GridWorld-v0')
wrapped_env = FlattenObservation(env)
print(wrapped_env.reset()) # E.g. [3 0 3 3], {}
包装器的一大优点是它们使环境高度模块化。例如,与其展平GridWorld的观察结果,您可能只希望查看目标和代理之间的相对位置。在观察包装器部分,我们已经实现了这样一个包装器。这个包装器也可以在gymnasium_env/wrappers/relative_position.py中找到:
import gymnasium
import gymnasium_env
from gymnasium_env.wrappers import RelativePosition
env = gymnasium.make('gymnasium_env/GridWorld-v0')
wrapped_env = RelativePosition(env)
print(wrapped_env.reset()) # E.g. [-3 3], {}