VTA 硬件指南
导航
VTA 硬件指南#
提供了自顶向下的 VTA 硬件设计概述。本硬件设计指南涵盖了两个层次的 VTA 硬件:
VTA 设计及其 ISA 软硬件接口的架构概述。
VTA 硬件模块的微架构概述,以及计算核心的微代码规范。
VTA 概述#
VTA 是通用的深度学习加速器,用于快速和高效的密集线性代数。VTA 集成了简单的类 RISC 处理器,可以在 1 级或 2 级张量寄存器上执行密集的线性代数操作。此外,该设计采用解耦的 access-execute 来隐藏内存访问延迟。
在更广泛的范围内,VTA 可以作为全栈优化的深度学习加速器设计模板,向编译器堆栈公开通用张量计算接口。
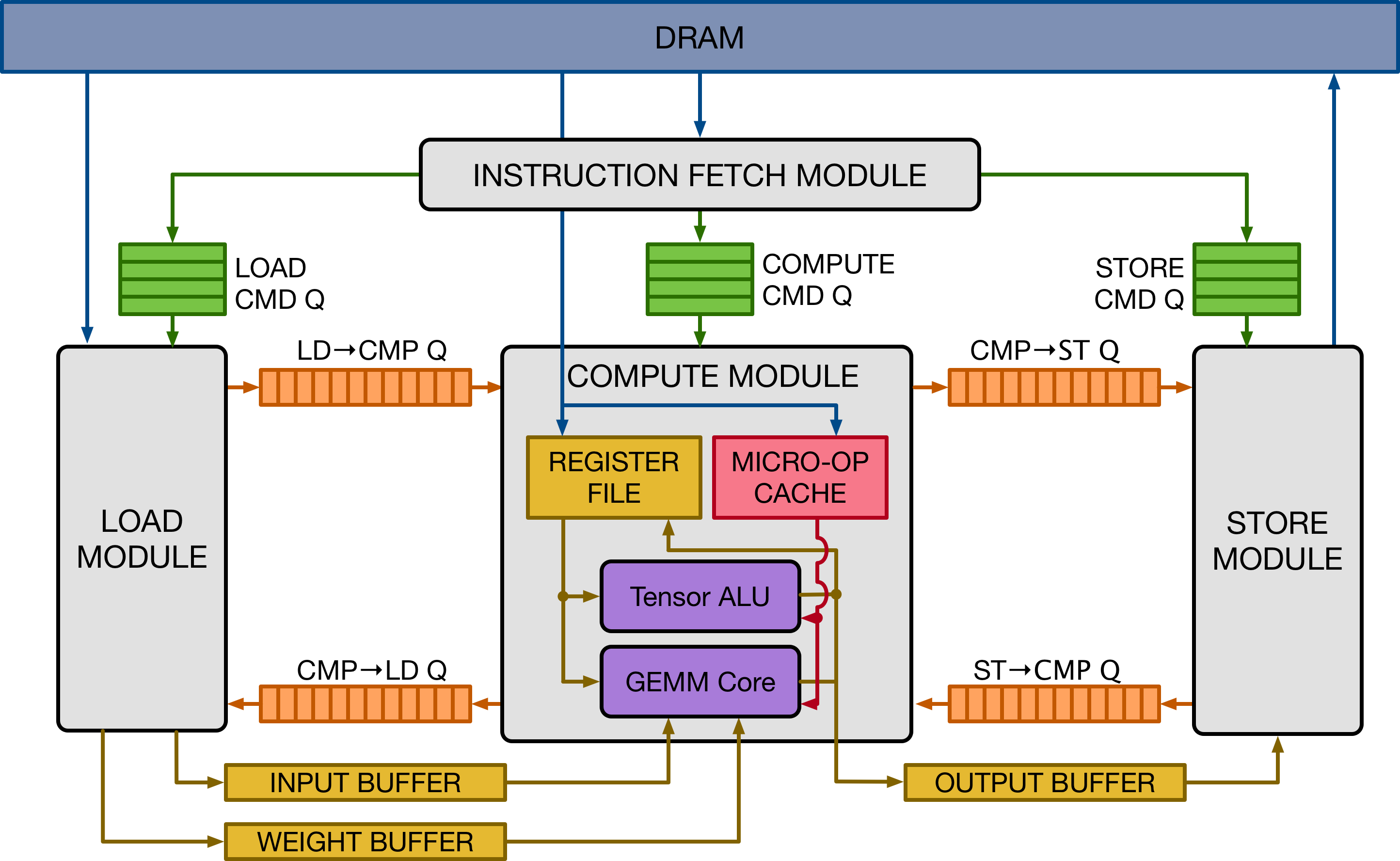
上图给出了 VTA 硬件组织的高级概述。VTA 由四个模块组成,通过 FIFO 队列和局部内存块(local memory blocks,简称 SRAM)相互通信,以实现任务级管道并行:
fetch 模块负责从 DRAM 中加载指令流。它还解码这些指令,将它们路由到三个命令队列中的一个。
load 模块负责将 DRAM 的输入张量和权重张量加载到数据专用的 on-chip 内存中。
compute 模块使用 GEMM 核心进行密集线性代数计算,使用张量 ALU 进行通用计算。它还负责将数据从 DRAM 加载到 register 文件,并将 micro-op 内核加载到 micro-op cache。
store 模块将计算 core 产生的结果存储回 DRAM。
HLS 硬件资源组织#
VTA 设计目前是在 Vivado HLS C++ 中指定的,而这只被 Xilinx 工具链所支持。VTA 硬件资源包含在 3rdparty/vta-hw/hardware/xilinx/sources 下:
vta.cc包含了每个 VTA 模块的定义,以及用于顶层 VTA 设计的顶层行为模型。
vta.h包含使用 Xilinxap_int类型的类型定义和函数原型声明。
此外,预处理器宏定义在 3rdparty/vta-hw/include/vta/hw_spec.h 下。这些宏的定义大多来自于 3rdparty/vta- hw/config/vta_config.json 文件中列出的参数。该 json 文件被 3rdparty/vta-hw/config/vta_config.py 处理,以产生定义预处理器宏的编译标志字符串。该字符串被 makefile 用于设置 HLS 硬件合成编译器和构建 VTA 运行时的 C++ 编译器中的高级参数。
HLS Module 示例#
我们展示了 C++ 中定义的 VTA 模块之一的定义:
void fetch(
uint32_t insn_count,
volatile insn_T *insns,
hls::stream<insn_T> &load_queue,
hls::stream<insn_T> &gemm_queue,
hls::stream<insn_T> &store_queue) {
#pragma HLS INTERFACE s_axilite port = insn_count bundle = CONTROL_BUS
#pragma HLS INTERFACE m_axi port = insns offset = slave bundle = ins_port
#pragma HLS INTERFACE axis port = load_queue
#pragma HLS INTERFACE axis port = gemm_queue
#pragma HLS INTERFACE axis port = store_queue
#pragma HLS INTERFACE s_axilite port = return bundle = CONTROL_BUS
INSN_DECODE: for (int pc = 0; pc < insn_count; pc++) {
#pragma HLS PIPELINE II = 1
// Read instruction fields
insn_T insn = insns[pc];
// Do some partial decoding
opcode_T opcode = insn.range(VTA_INSN_MEM_0_1, VTA_INSN_MEM_0_0);
memop_id_T memory_type = insn.range(VTA_INSN_MEM_5_1, VTA_INSN_MEM_5_0);
// Push to appropriate instruction queue
if (opcode == VTA_OPCODE_STORE) {
store_queue.write(insn);
} else if (opcode == VTA_OPCODE_LOAD &&
(memory_type == VTA_MEM_ID_INP || memory_type == VTA_MEM_ID_WGT)) {
load_queue.write(insn);
} else {
gemm_queue.write(insn);
}
}
}
- 关于HLS编码的几点观察:
Parameters: 每个函数的参数列表,结合 interface pragmas 定义由生成的硬件模块公开的硬件接口。
通过 value 传递的参数表示主机可以写入的只读硬件内存映射寄存器。例如,这个 fetch 函数有
insn_count参数,它将被合成为主机写入的内存映射寄存器,以便设置给定 VTA 指令序列的长度。指针参数可能意味着两种情况之一,这取决于所使用的 interface pragma。
When used with a
m_axiinterface pragma, an AXI requestor interface gets generated to provide DMA access to DRAM.当与
braminterface pragma 一起使用时,将生成 bram 接口来公开到 FPGA block-RAM 的读和/或写端口。
HLS 流通过引用与
axisinterface pragma 结合来传递,产生模块的 FIFO 接口。硬件 FIFO 提供了有用的模块间同步机制。
Pragmas: 编译器 pragmas 对于定义每个模块的硬件实现至关重要。下面列出了 VTA 设计中用于与编译器沟通实现需求的几个 pragmas。
HLS INTERFACE: 指定 synthesized 硬件模块的接口。HLS PIPELINE: 通过设置启动间隔目标定义硬件管道性能目标。当设置了II == 1目标时,它告诉编译器,合成硬件管道应该能够每个周期执行一个循环迭代。”HLS DEPENDENCE:指示编译器在给定循环中忽略某些类型的依赖检查。考虑循环体,它对相同的 BRAM 结构进行读写,并且需要实现 II 为 1。HLS 编译器必须假设最坏的情况,即一个读被发送到一个地址,而过去的写更新了之前的周期:这是无法实现的 BRAM 计时特征(它需要至少 2 个周期才能看到更新的值)。因此,为了实现 II 为 1,必须放松依赖检查。请注意,当这个优化开启时,它会落到软件堆栈上,以防止写后再读到同一个地址。
备注
这个 参考指南 提供了更深入、更完整的 Xilinx 2018.2 工具链的 HLS 规范。
架构总览#
指令集架构#
VTA 的指令集架构(instruction set architecture,简称 ISA)由 4 条执行延迟可变的 CISC 指令组成,其中两条执行微编码(micro-coded)指令序列来执行计算。
VTA 的说明如下:
LOAD指令:将 2D 张量从 DRAM 加载到输入缓冲区、权重缓冲区或寄存器文件中。它还可以将微内核加载到 micro-op 缓存中。当加载 input 和 weight tile 时,支持动态 padding。GEMM指令:对 input 张量和 weight 张量执行矩阵-矩阵乘法的微运算序列,并将结果添加到寄存器文件张量中。ALU指令:对寄存器文件张量数据执行矩阵-矩阵 ALU 运算的微运算序列。STORE指令:将 2D 张量从 output buffer 存储到 DRAM。
LOAD 指令由 load 和 compute 模块执行,具体取决于存储内存缓冲区的位置目标。GEMM 和 ALU 指令由计算模块的 GEMM 核心和张量 ALU 执行。最后,STORE 指令由 store 模块独个执行。每条指令的字段如下图所示。每个字段的含义将在 Microarchitectural 概述 部分进一步解释。
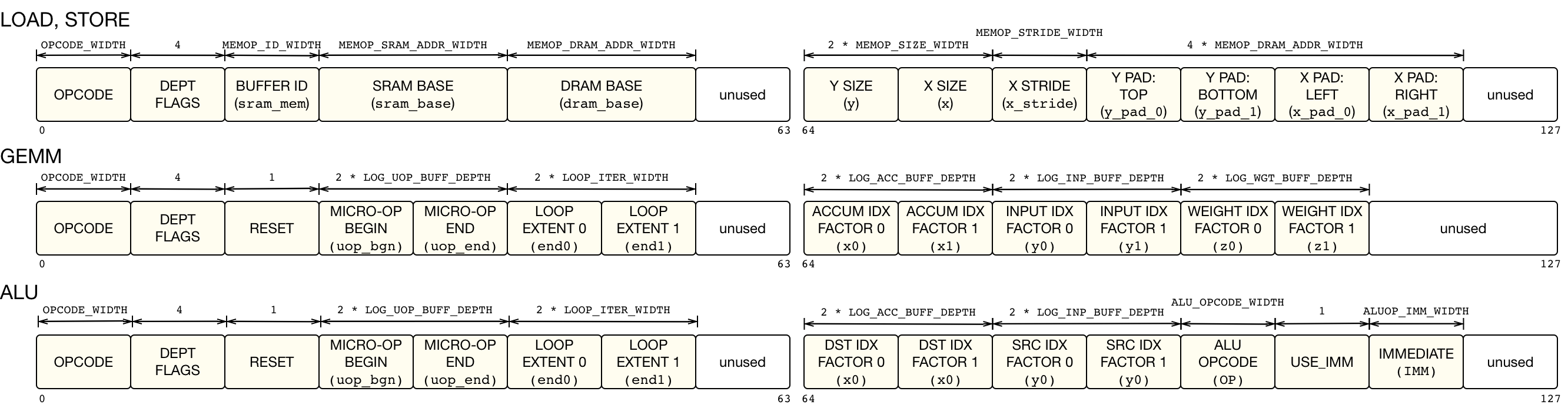
备注
请注意,随着 VTA 的架构参数(即 GEMM 核心 shape、数据类型、内存大小等)的修改,VTA ISA 也会发生变化,因此 ISA 不能保证 VTA 的所有变体之间的兼容性。然而,这是可以接受的,因为 VTA 运行时会适应参数的变化,并生成为生成的加速器版本量身定制的二进制代码。这体现了 VTA 堆栈采用的联合设计理念,它包含了软硬件接口的流动性。
数据流执行#
VTA 依赖于硬件模块之间的 FIFO 队列来同步并发任务的执行。下图显示了给定的硬件模块如何通过使用依赖 FIFO 队列和 single-reader/single-writer SRAM 缓冲区,以数据流的方式从其 consumer 和 producer 模块并发执行。每个模块通过 read-after-write(RAW)和 write-after-read(WAR)依赖队列连接到它的消费者和生产者。
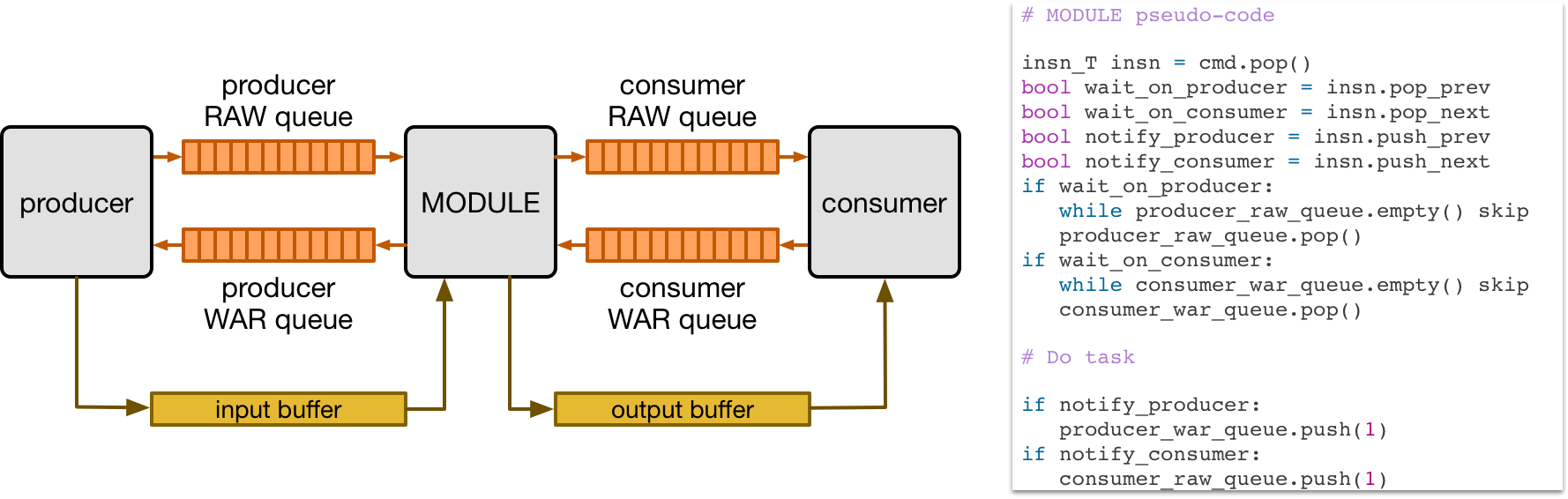
上面的伪代码描述了模块如何执行基于其他指令依赖关系的给定指令。首先,每个指令中的依赖标志在硬件中解码。如果指令有传入的 RAW 依赖项,则在从 producer 模块接收到 RAW 依赖令牌后执行。类似地,如果任务传入 WAR 依赖项,则执行是在从 consumer 模块接收到 WAR 依赖令牌之后进行的。最后,当任务完成时,检查输出的 RAW 和 WAR 依赖,并分别通知 consumer 和 producer 模块。
备注
请注意,此场景中的依赖令牌是无信息的。这是因为每个模块执行的指令不能按照设计重新排序,因为它们以 FIFO 顺序到达。
管道可扩展性#
VTA 默认的设计由四个模块组成,描述了 3 阶段的 load-compute-store 任务管道。根据数据流硬件组织原则,可以将 VTA 的管道扩展为包含更多阶段。例如,可以设想将张量 ALU 从 GEMM 核中分离出来,以便最大限度地利用 GEMM 核。这将导致 load-gemm-activate-store 任务管道,这与 TPU 设计密切相关。然而,添加更多阶段是有成本的:它会增加存储和额外的逻辑开销,这也是我们选择默认的 3 阶段管道的原因。
Microarchitectural 概述#
我们描述了构成 VTA 设计的模块。模块定义被包含在 3rdparty/vta-hw/hardware/xilinx/sources/vta.cc 中。
Fetch 模块#
VTA 是由线性指令流编写的。fetch 模块是 VTA 到 CPU 的入口点,通过三个内存映射寄存器进行编程:
read-write
control寄存器启动 fetch 模块,并被读取以检查其是否完成write-only
insn_count寄存器设置要执行的指令数。write-only
insns寄存器设置 DRAM 中指令流的起始地址。
CPU 在由 VTA 运行时准备的物理连续缓冲区中准备 DRAM 中的指令流。当指令流准备好后,CPU 将开始的物理地址写入 insns 寄存器,将指令流的长度写入 insn_count 寄存器,并将开始信号写入 control 寄存器。这个过程启动 VTA,通过 DMA 从 DRAM 读取指令流。
在访问指令流时,fetch 模块会对指令进行部分解码,并将这些指令推送到命令队列中,再由这些命令队列向 load、compute 和 store 模块提供信息。
STORE指令被推送到 store 命令队列,由 store 模块处理。GEMM和ALU指令被推送到 compute 命令队列,由 compute 模块处理。描述微操作内核的 load 运算或寄存器文件数据的
LOAD指令被推到 compute 命令队列,由 compute 模块处理。描述输入或权重数据的 load 运算的
LOAD指令被推到 load 命令队列,由 load 模块处理。
当其中一个命令队列已满时,fetch 模块会一直等待,直到该队列未满。因此,命令队列的大小足够深,以允许宽的执行窗口,并允许多个任务在 load-compute-store 管道上并发运行。
Compute 模块#
VTA 的 compute 模块充当 RISC 处理器,在张量寄存器而不是标量寄存器上执行计算。两个功能单元改变了寄存器文件:张量 ALU 和 GEMM core。
compute 模块从微操作缓存执行 RISC 微操作。有两种类型的 compute 微操作:ALU 和 GEMM 运算。为了最小化微操作内核的占用,同时避免对控制流指令(如条件跳转)的需要,compute 模块在两级嵌套循环中执行微操作序列,该循环通过仿射函数计算每个张量寄存器的位置。这种压缩方法有助于减少微核指令的占用,并适用于矩阵乘法和二维卷积,这在神经网络算子中很常见。
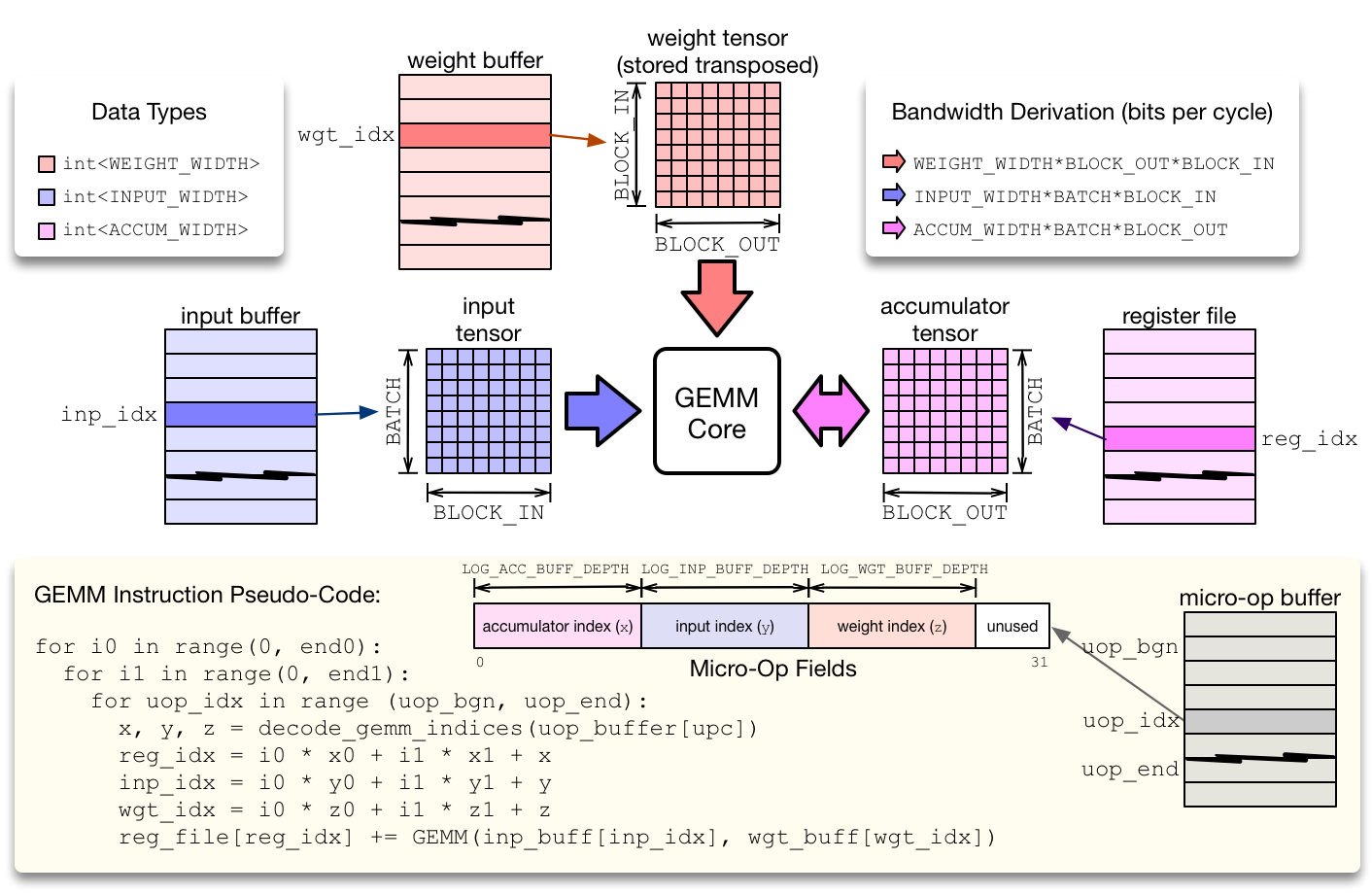
GEMM 核心 通过在上图中描述的 2 级嵌套循环中执行微代码序列来评估 GEMM 指令。GEMM 核心每个周期可以执行一次输入权重矩阵乘法。单周期矩阵乘法的维数定义了硬件 tensorization intrinsic,TVM 编译器必须降低计算调度。这种内在的张量化是由 input、weight 和 accumulator 张量的 dimension 定义的。每种数据类型都可以具有不同的整数精度:通常权值和输入类型都是低精度的(8 位或更少),而累加器张量具有更宽的类型以防止溢出(32 位)。为了保持 GEMM 核心的繁忙,每个输入缓冲区、权重缓冲区和寄存器文件都必须暴露足够的 read/write bandwidth。
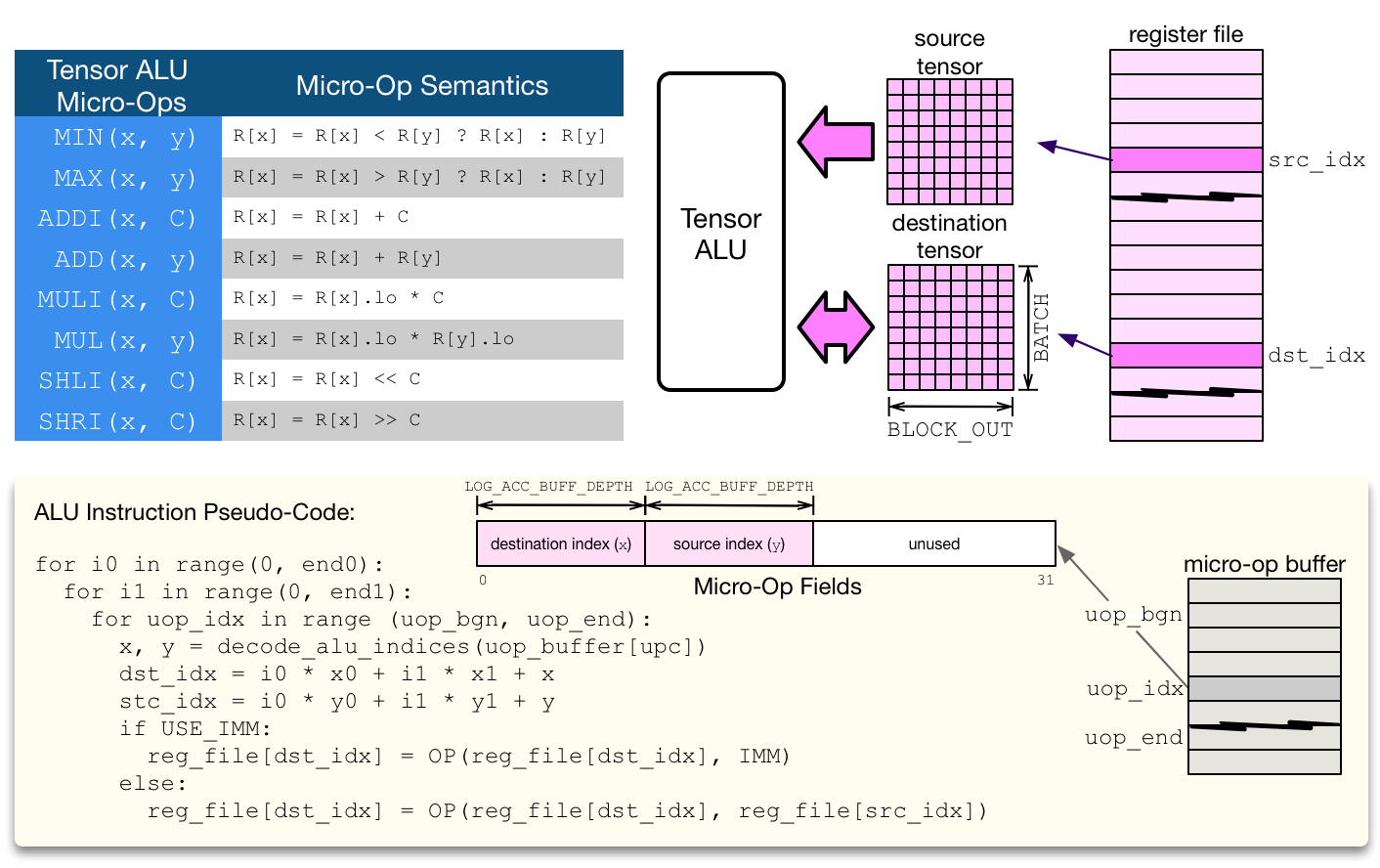
张量 ALU 支持一组标准运算来实现通用的激活、归一化和池化算子。VTA 是一种模块化设计,张量 ALU 支持的运算范围可以扩展到更高的运算覆盖范围,但代价是更高的资源利用率。张量 ALU 可以进行张量-张量运算,也可以对临时值进行张量-标量运算。张量 ALU 的 opcode 和临时值由高层的 CISC 指令指定。在张量 ALU 计算上下文中的微代码只负责指定数据访问模式。
备注
在计算吞吐量方面,张量 ALU 并不以每个周期一个运算的速度执行。限制来自读取端口的缺乏:由于每个周期可以读取一个寄存器文件张量,张量 ALU 的启动间隔至少为 2(即每 2 个周期最多执行 1 次运算)。此外,一次执行一个张量-张量运算的代价可能很高,特别是考虑到寄存器文件类型很宽,通常是 32 位整数。因此,为了平衡张量 ALU 和 GEMM core 的资源利用 footprint,张量-张量运算在默认情况下是通过多个循环的向量-向量运算来执行的。
Load 和 Store 模块#

load 和 store 模块执行 2D DMA loads,采用从 DRAM 到 SRAM 的跨步访问模式。此外,load 模块可以动态插入 2D padding,这在阻塞 2D 卷积时非常有用。这意味着 VTA 可以平铺 2D 卷积输入,而不需要在 DRAM 中重新布局数据,在输入和权重块周围插入空间填充。