Relay IR 简介
导航
Relay IR 简介#
本文介绍了第二代 NNVM: Relay IR。希望读者具有两种背景——具有编程语言背景和熟悉计算图表示的深度学习框架开发人员。
在这里简要地总结了设计目标,并将在本文的后面部分涉及这些要点。
支持传统的数据流图风格编程和变换。
支持函数式的作用域,let-binding,并使其成为功能齐全的可微分语言。
允许用户混合两种编程风格。
使用 Relay 构建计算图#
传统的深度学习框架使用计算图作为其中间表示。计算图(或数据流图)是表示计算的有向无环图(directed acyclic graph,简称 DAG)。 虽然由于缺乏控制流,数据流图在它们能够表达的计算方面受到了限制,但它们的简单性使其更容易实现对异构执行环境的自动微分和编译(例如,在专门的硬件上执行图的一部分)。

您可以使用 Relay 来构建计算(数据流)图。具体来说,上面的代码展示了如何构造简单的双节点图。 可以发现,该示例的语法与现有的计算图 IR(如 NNVMv1)没有太大区别,惟一的区别是术语上的不同:
现有框架通常使用 graph 和 subgraph
Relay 使用函数,例如——
fn (%x)来表示 graph
每个数据流节点都是 Relay 中的 CallNode。Relay Python DSL 允许快速构造数据流图。
在上面的代码中,要强调的一件事是,我们显式地构造了 Add 节点,它的两个输入点都指向 %1。
当深度学习框架评估上述程序时,它将按拓扑顺序计算节点,%1 只计算一次。
虽然这一事实对于深度学习框架的构建者来说是非常自然的,但它可能会让 PL 研究人员首先感到惊讶。
如果实现简单的 visitor 来打印结果,并将结果作为嵌套的 Call 表达式处理,那么它将变成 log(%x) + log(%x)。
当 DAG 中存在共享节点时,对程序语义的不同解释导致了这种分歧。在普通的函数式编程 IR 中,嵌套表达式被视为表达式树,而不考虑 %1 实际上在 %2 中被重用了两次的事实。
Relay IR 注意到了这种差异。通常,深度学习框架用户以这种方式构建计算图,其中经常出现 DAG 节点重用。
因此,当以文本格式打印 Relay 程序时,每行打印一个 CallNode,并为每个 CallNode 分配一个临时 id (%1, %2),以便在程序的后面部分中引用每个公共节点。
模块:支持多函数(Graphs)#
到目前为止,已经介绍了如何将数据流图构建为函数。 人们可能会很自然地问:能支持多个函数并使它们能够相互调用吗?Relay 允许在模块(module)中分组多个函数;下面的代码显示了一个函数调用另一个函数的示例。
def @muladd(%x, %y, %z) {
%1 = mul(%x, %y)
%2 = add(%1, %z)
%2
}
def @myfunc(%x) {
%1 = @muladd(%x, 1, 2)
%2 = @muladd(%1, 2, 3)
%2
}
Module 可以被视为 Map<GlobalVar, Function>。这里 GlobalVar 只是一个 id,用来表示模块中的函数。
在上面的例子中 @muladd 和 @myfunc 是 GlobalVars。当 CallNode 用于调用另一个函数时,相应的 GlobalVar 存储在该 CallNode 的 op 字段中。
它包含了一个间接级别,我们需要使用对应的 GlobalVar 从模块中查找被调用函数的函数体。在这种特殊情况下,还可以直接将对 Function 的引用存储为 CallNode 中的 op。
那么,为什么需要引入 GlobalVar?主要原因是 GlobalVar 解耦了函数的定义/声明,并支持递归和延迟声明(delayed declaration)。
def @myfunc(%x) {
%1 = equal(%x, 1)
if (%1) {
%x
} else {
%2 = sub(%x, 1)
%3 = @myfunc(%2)
%4 = add(%3, %3)
%4
}
}
在上面的例子中,@myfunc 递归地调用自己。使用 GlobalVar @myfunc 表示函数可以避免数据结构中的循环依赖。
至此,我们已经介绍了 Relay 中的基本概念。值得注意的是,Relay 对 NNVMv1 有以下改进:
简洁的文本格式,易于调试写入 passes。
在联合的模块中对 subgraphs-functions 的一级支持,这获得进一步的联合优化机会,如内联(inlining)和调用约定规范(calling convention specification)。
简单的前端语言互操作(interop),例如,所有的数据结构都可以在 Python 中访问,这允许在 Python 中快速构建优化原型,并将它们与 C++ 代码混合。
Let Binding and Scopes#
到目前为止,已经介绍了如何用深度学习框架中使用的老式方法来构建计算图。本节将讨论 Relay 引入的新的重要构造—— let 绑定。
Let 绑定在每一种高级编程语言中都使用。在 Relay 中,它是包含三个字段 Let(var, value, body) 的数据结构。
当求 let 表达式的值时,首先 evaluate value 部分,将其赋值给 var,然后在 body 表达式中返回求值结果。
可以使用 let 绑定序列来构造与数据流图程序在逻辑上等价的程序。下面的代码示例显示了带有两种形式的程序。
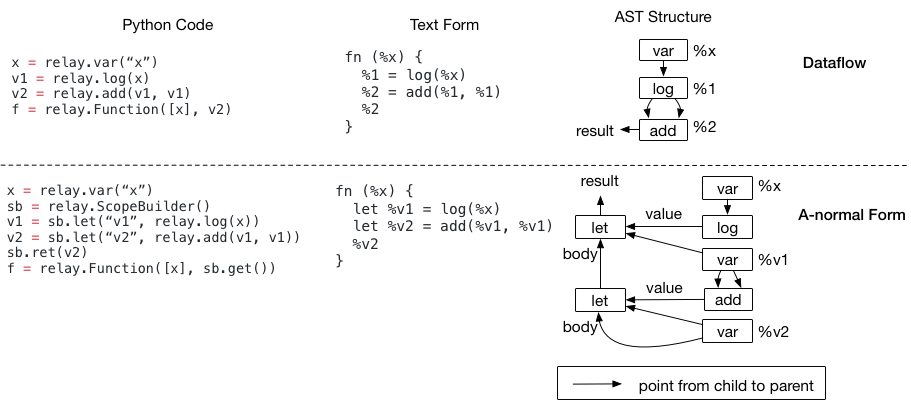
嵌套的 let 绑定称为 A-normal(A-范式) 形式,它通常在函数式编程语言中用作 IRs。现在,请仔细看一下 AST 结构。 虽然这两个程序在语义上是相同的(它们的文本表示也是相同的,只是 A-normal 有前缀),但它们的 AST 结构是不同的。
由于程序优化使用这些 AST 数据结构并变换它们,这两种不同的结构将影响将要编写的编译器代码。例如,如果想检测模式 add(log(x), y):
在数据流图形式中,可以首先访问
add节点,然后直接查看它的第一个参数,以确定它是否是 log在 A-normal 形式中,我们不能再直接进行检查了,因为 add 的第一个输入是
%v1——我们需要保存一个从变量到其绑定值的映射,并查找该映射,以便知道%v1是 log。
不同的数据结构将影响您编写变换的方式,我们需要记住这一点。所以现在,作为深度学习框架的开发人员,您可能会问,为什么我们需要 let 绑定? 你的 PL 朋友总是会告诉你,let 很重要,因为 PL 是相当成熟的领域,这背后一定有一些智慧。
为什么可能需要 Let 绑定#
let 绑定的一个关键用法是指定计算范围。让我们看一下下面的示例,它不使用 Let 绑定。
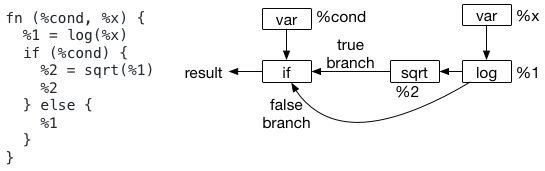
当我们试图决定在哪里计算节点 %1 时,问题就来了。
特别是,虽然文本格式似乎建议我们应该在 if 范围外计算节点 %1,但 AST(如图所示)不建议这样做。
实际上,数据流图从来没有定义它的评估范围。这在语义上引入了一些歧义。
当我们有闭包时,这种模糊性变得更加有趣。考虑下面的程序,它返回一个闭包。我们不知道应该在哪里计算 %1;它可以在闭包的内部或外部。
fn (%x) {
%1 = log(%x)
%2 = fn(%y) {
add(%y, %1)
}
%2
}
let 绑定解决了这个问题,因为值的计算发生在 let 节点。
在两个程序中,如果我们将 %1 = log(%x) 更改为 let %v1 = log(%x),就可以明确指定计算位置在 if 范围和闭包之外。
正如你所看到的,let-binding 给出了更精确的计算站点规范,当我们生成后端代码时可能会很有用(因为这样的规范在 IR 中)。
另一方面,数据流图形式,它没有指定计算范围,确实有它自己的优点——即,我们不需要担心在生成代码时将 let 放在哪里。 数据流图形式还为后面的传递提供了更多的自由,以决定将评估点放在哪里。因此,在优化的初始阶段,当您觉得方便时,使用程序的数据流形式可能不是坏主意。 目前,Relay 中的许多优化都是为了优化数据流图程序而编写的。
然而,当我们将 IR 降低到实际的运行时程序时,需要精确地确定计算的范围。 特别是,希望显式指定在使用子函数和闭包时计算范围应该发生在哪里。let 绑定可以在后期执行特定的优化中解决这个问题。
IR 变换的意义#
希望现在你已经熟悉了这两种表示。大多数函数式编程语言以 A-normal 形式进行分析,其中 analyzer 不需要注意表达式是 DAG。
Relay 选择同时支持数据流图形式和 let 绑定。我们相信让框架开发人员选择他们熟悉的表示是很重要的。然而,这确实对我们如何写 passes 有一些影响:
如果你来自数据流图背景,想要处理 let,保留 var 到表达式的映射,这样你就可以在遇到 var 时执行查找。这可能意味着最小的更改,因为我们已经需要从表达式到变换后的表达式的映射。注意,这将有效地删除程序中的所有 let。
如果您来自 PL 背景,并且喜欢 A-normal 形式,我们将提供数据流图到 A-normal 形式的 pass。
对于 PL 人来说,当你在实现某些东西(比如数据流图到 ANF 变换)时,要注意表达式可以是 DAG,这通常意味着我们应该用
Map<Expr, Result>并且只计算一次转换后的结果,因此得到的表达式保持了通用结构。
还有一些其他的高级概念,如 symbolic shape inference,polymorphic functions,这些都没有在本材料中涵盖;欢迎您查阅其他资料。