定制格式#
您可以通过将以下配置添加到 conf.py 中,指定其他文件类型转换为笔记本,然后以与常规笔记本相同的方式执行/解析:
nb_custom_formats = {
".mysuffix": "mylibrary.converter_function"
}
字符串应是 Python 函数,将通过
import mylibrary.converter_function加载该函数应接受文件内容(作为
str)并返回 nbformat.NotebookNode
如果该函数接受其他关键字参数,则可以在第二个参数中将其指定为字典。例如,默认转换如下所示:
nb_custom_formats = {
'.ipynb': ['nbformat.reads', {'as_version': 4}],
}
重要
默认情况下,笔记本中的 Markdown 单元将使用与其他 Markdown 文件相同的 MyST 解析器配置进行解析(参见可用配置选项)。
但是,如果这与您的文件格式不兼容,则可以使用第三个参数指定将 Markdown 解析为 严格 CommonMark:
nb_custom_formats = {
'.ipynb': ['nbformat.reads', {'as_version': 4}, True],
}
最后,对于基于文本的格式,MyST-NB 还会在输出笔记本的元数据中搜索可选的 source_map 键。该键应是列表,将每个单元映射到原始源文件中的起始行号,例如对于具有三个单元的笔记本:
{
"metadata": {
"source_map": [10, 21, 53]
}
}
此映射允许‘真实’错误报告,如 警告抑制 中所述。
使用 Jupytext#
常见的转换工具是 jupytext,它已被用于将此 .Rmd 文件转换为笔记本!
配置如下:
nb_custom_formats = {
".Rmd": ["jupytext.reads", {"fmt": "Rmd"}]
}
重要
为了与 myst-nb 完全兼容,应使用 jupytext>=1.11.2。
示例:
\```{python echo=TRUE}
import pandas as pd
series = pd.Series({'A':1, 'B':3, 'C':2})
pd.DataFrame({"Columne A": series})
\```
import pandas as pd
series = pd.Series({'A':1, 'B':3, 'C':2})
pd.DataFrame({"Columne A": series})
| Columne A | |
|---|---|
| A | 1 |
| B | 3 |
| C | 2 |
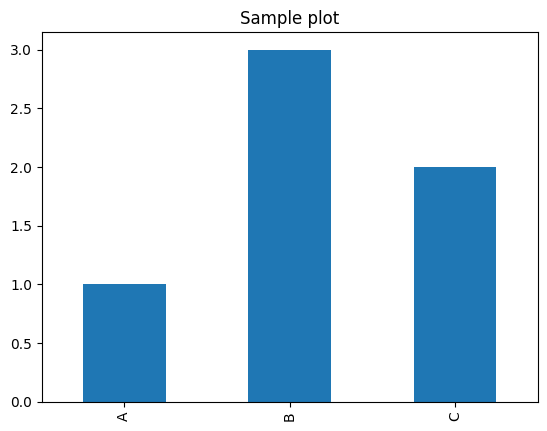
\```{python bar_plot, echo=FALSE, fig.height=5, fig.width=8}
series.plot(kind='bar', title='Sample plot')
\```
<Axes: title={'center': 'Sample plot'}>
致谢#
感谢 nbsphinx 提供了此功能的基础实现。