快速上手¶
示例¶
首先,尝试 MLC LLM 对 int4 量化的 Llama3 8B 的支持。建议至少有 6GB 的可用 VRAM 来运行它。
安装 MLC LLM。MLC LLM 可以通过 pip 安装。建议始终在隔离的 conda 虚拟环境中安装。
在 Python 中运行聊天补全。 以下 Python 脚本展示了 MLC LLM 的 Python API:
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC"
engine = MLCEngine(model)
# Run chat completion in OpenAI API.
for response in engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=True,
):
for choice in response.choices:
print(choice.delta.content, end="", flush=True)
print("\n")
engine.terminate()
文档和教程。 Python API 参考及其教程 可在线获取。
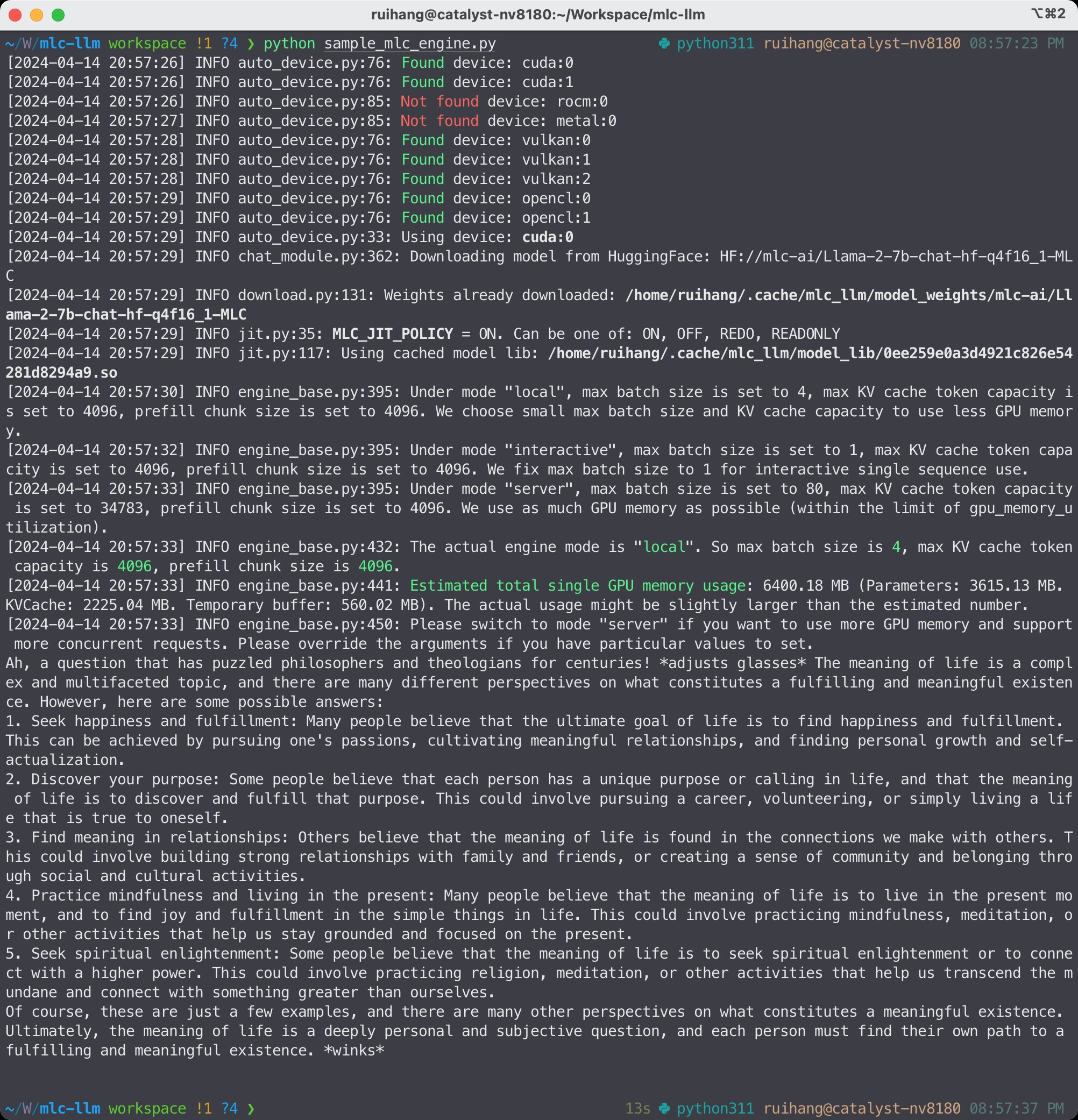
MLC LLM Python API¶
安装 MLC LLM。MLC LLM 可以通过 pip 安装。建议始终在隔离的 conda 虚拟环境中安装。
启动 REST 服务器。 在命令行中运行以下命令以在 http://127.0.0.1:8000 启动 REST 服务器。
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
向服务器发送请求。 当服务器准备就绪时(显示 INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)),打开新的 shell 并通过以下命令发送请求:
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC",
"messages": [
{"role": "user", "content": "Hello! Our project is MLC LLM. What is the name of our project?"}
]
}' \
http://127.0.0.1:8000/v1/chat/completions
文档和教程。 查看 REST API 获取 REST API 参考和教程。REST API 完全支持 OpenAI API。
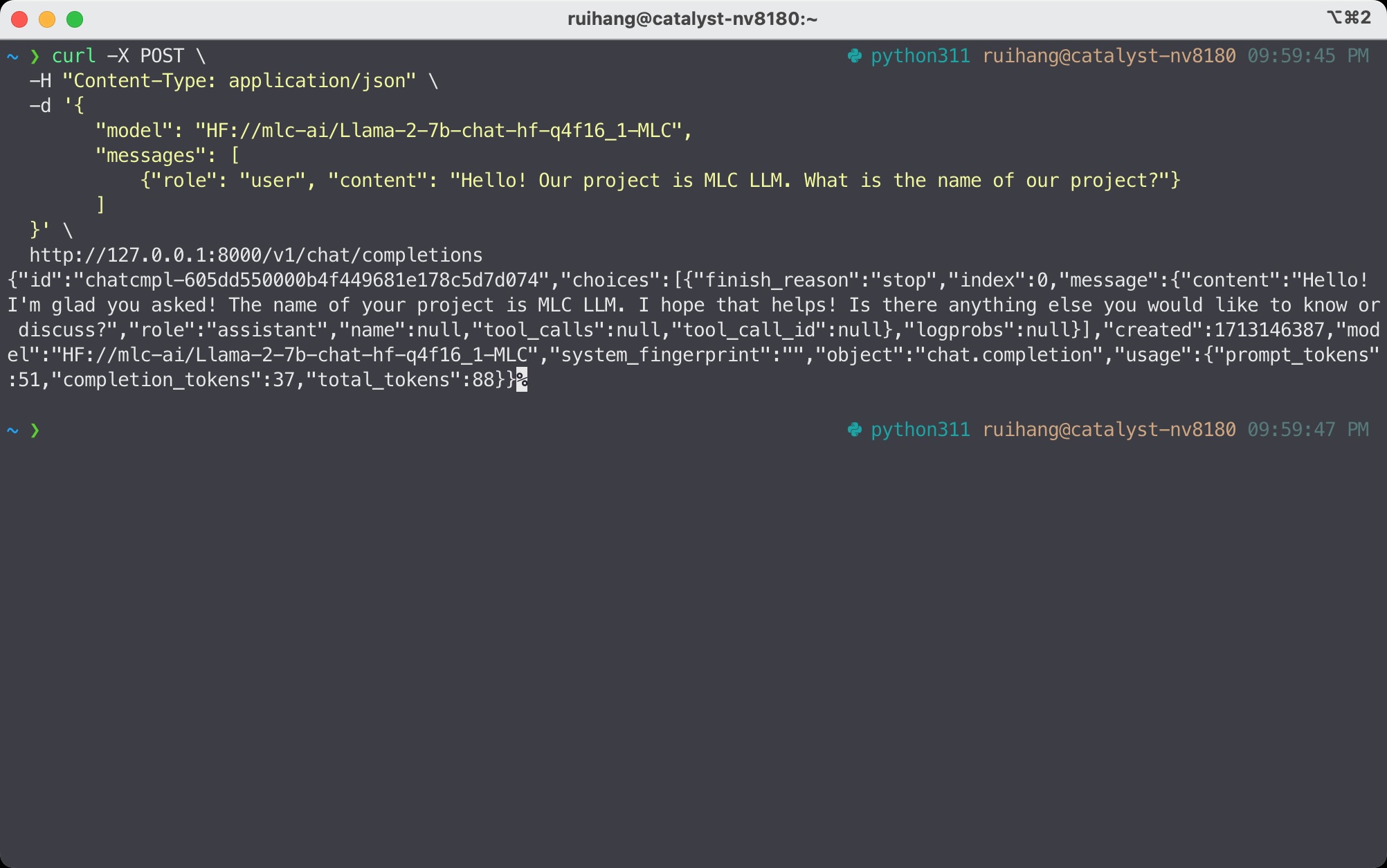
向 MLC LLM 的 REST 服务器发送 HTTP 请求¶
安装 MLC LLM。MLC LLM 可以通过 pip 安装。建议始终在隔离的 conda 虚拟环境中安装。
对于 Windows/Linux 用户,请确保已安装最新的 Vulkan 驱动程序。
在命令行中运行。
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
如果您使用的是 Windows/Linux/SteamDeck 并且希望使用 Vulkan,建议通过 conda 安装必要的 Vulkan 加载器依赖项,以避免找不到 Vulkan 的问题。
conda install -c conda-forge gcc libvulkan-loader
WebLLM。MLC LLM 为 WebGPU 和 WebAssembly 生成高性能代码,因此 LLM 可以在网页浏览器中本地运行,无需服务器资源。
下载预量化权重。此步骤在 WebLLM 中是自包含的。
下载预编译的模型库。WebLLM 会自动下载 WebGPU 代码来执行。
检查浏览器兼容性。最新的 Google Chrome 提供了 WebGPU 运行时,WebGPU Report 是有用的工具,可以验证浏览器的 WebGPU 功能。
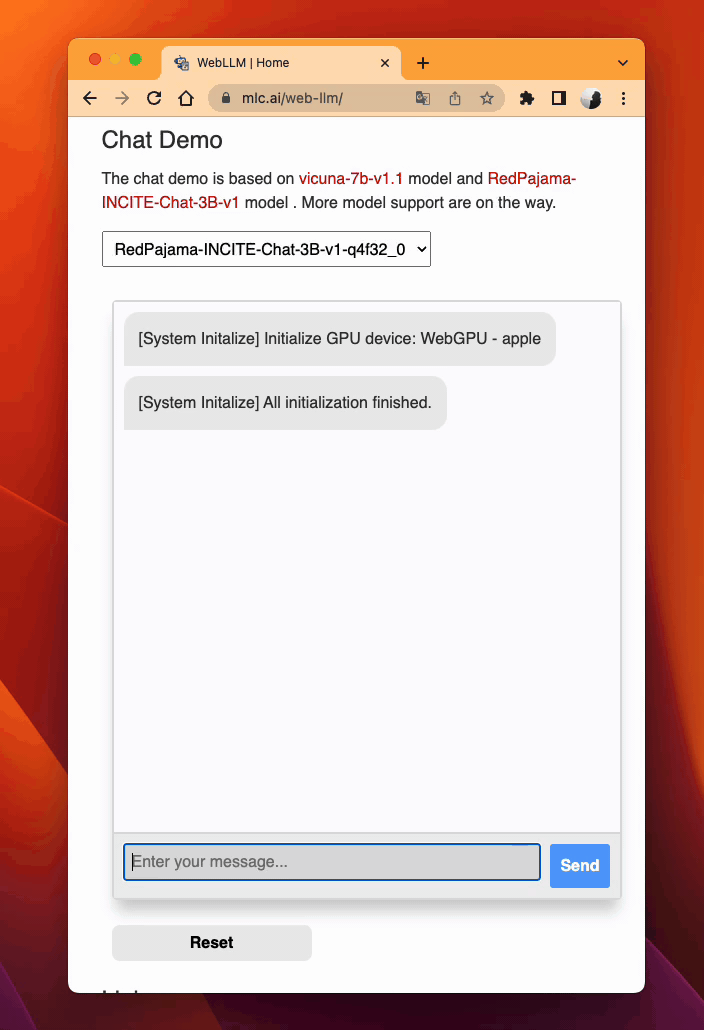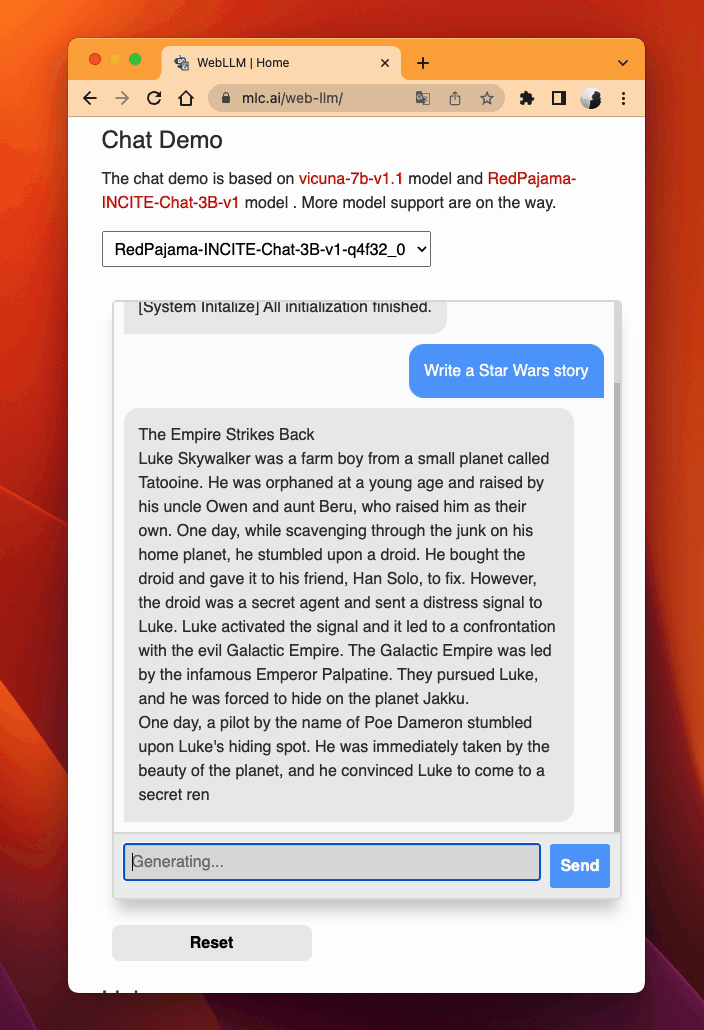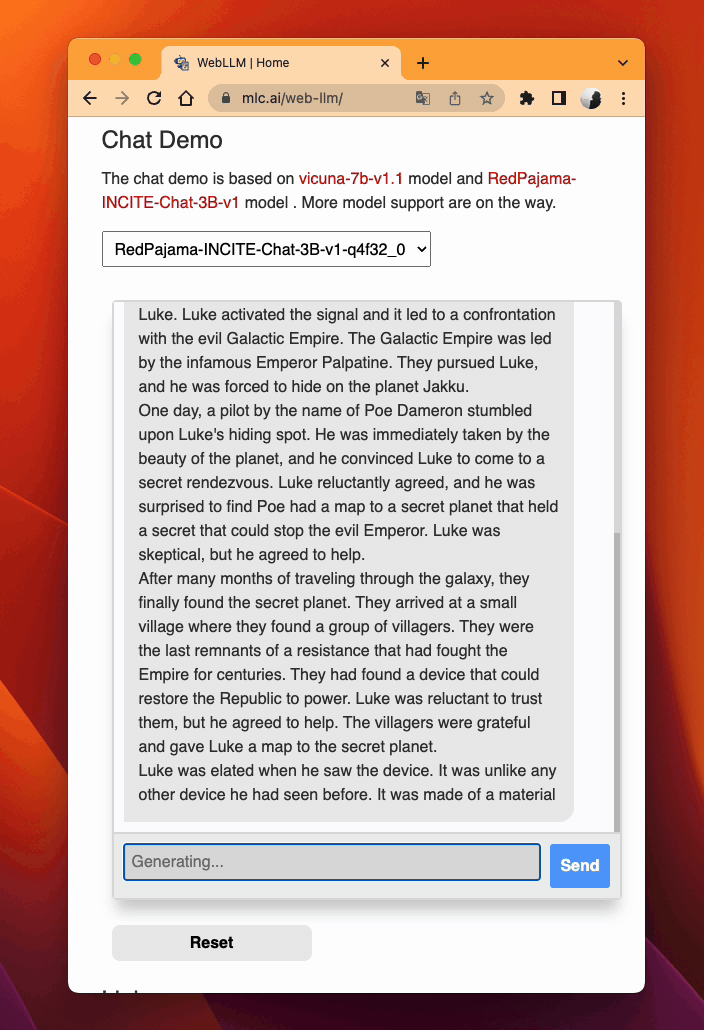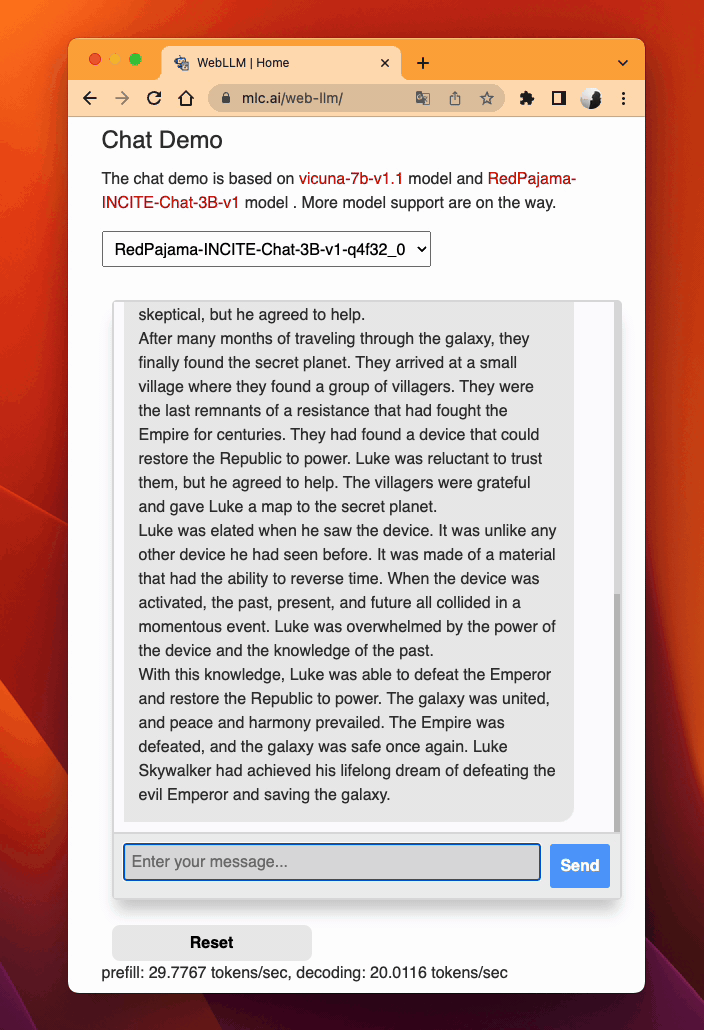
MLC LLM 在网页上¶

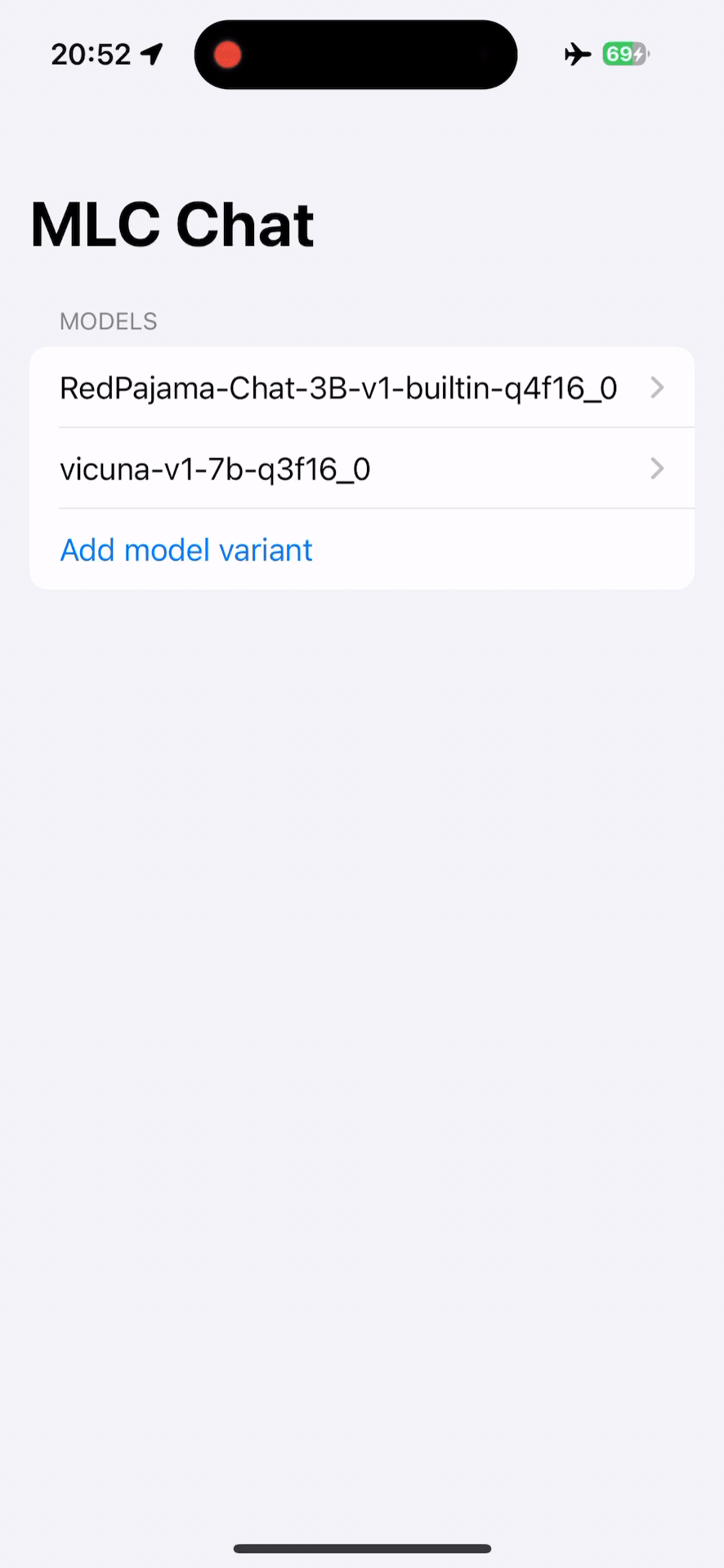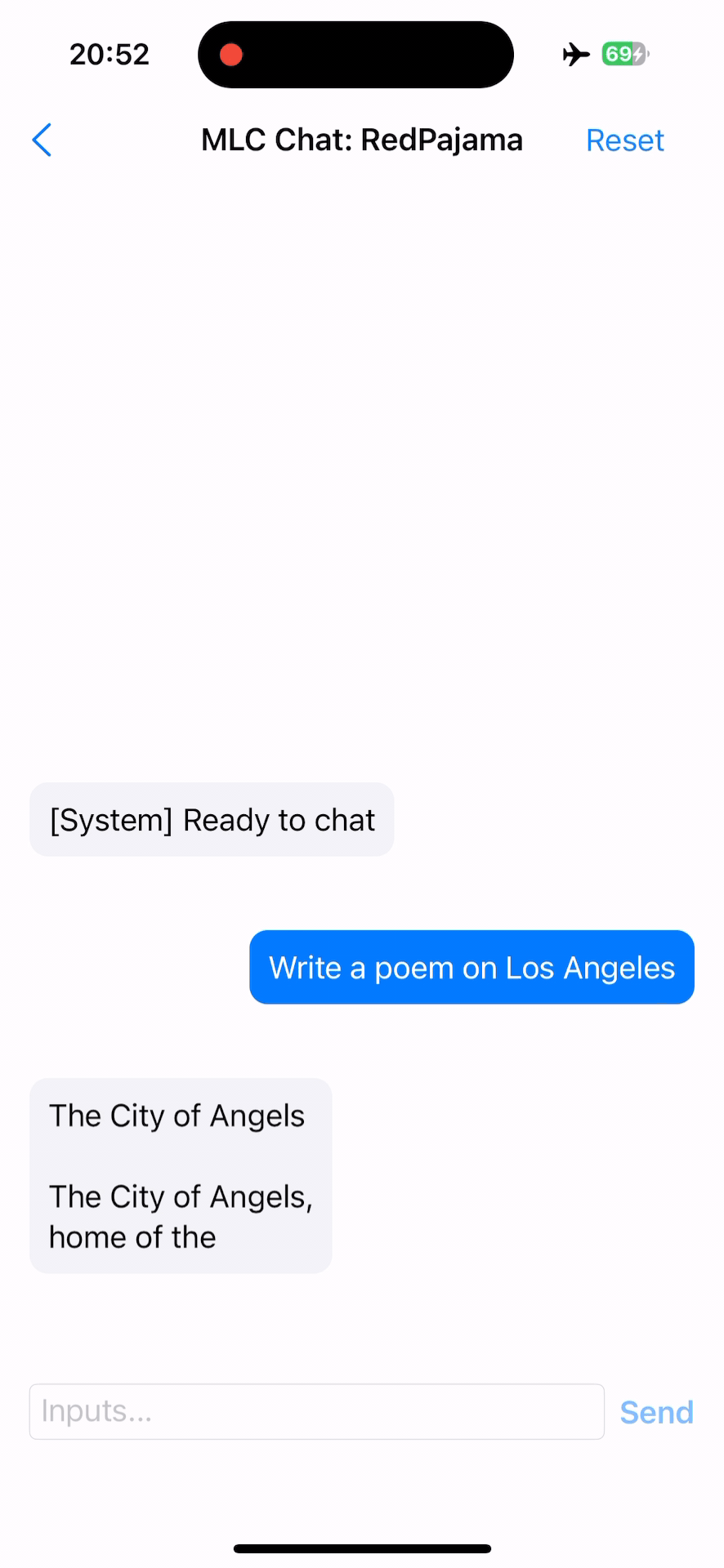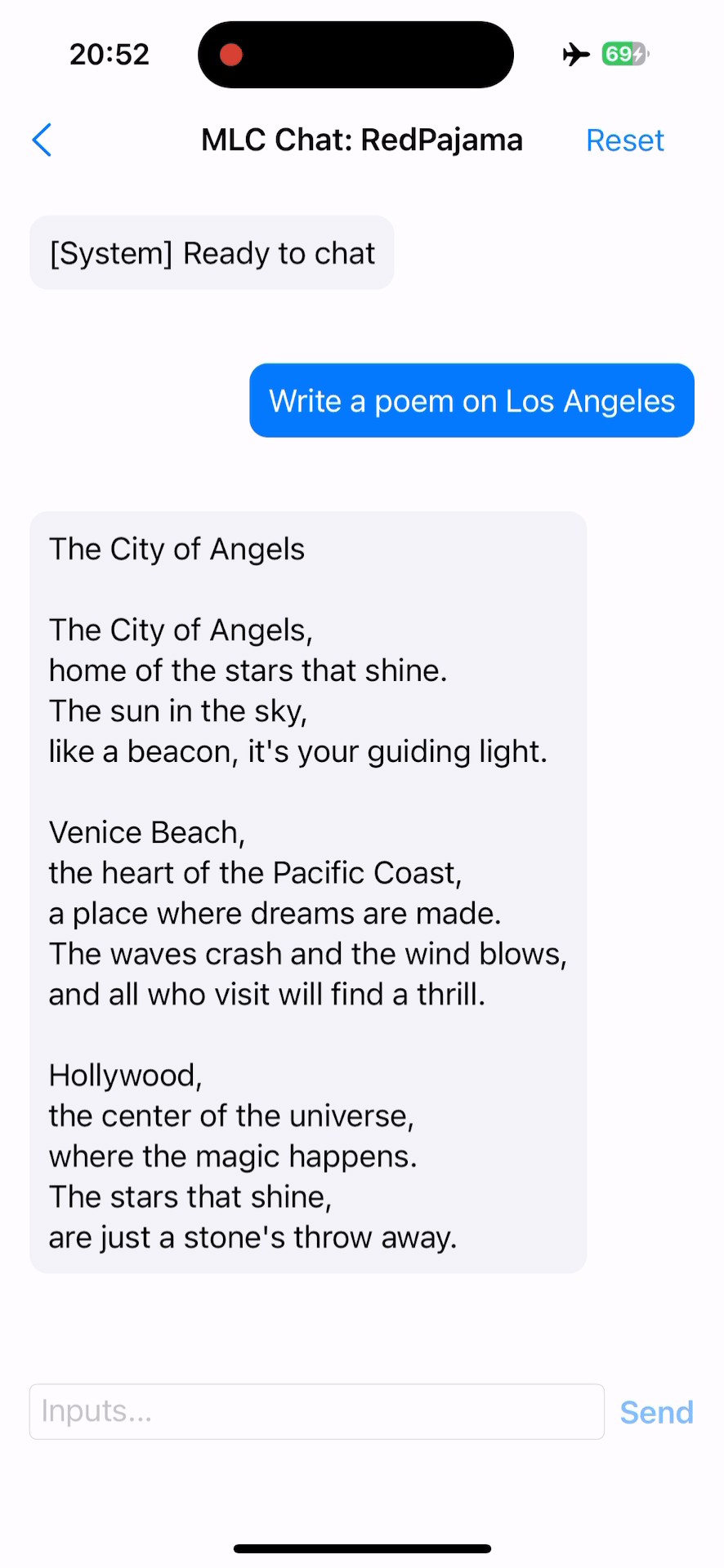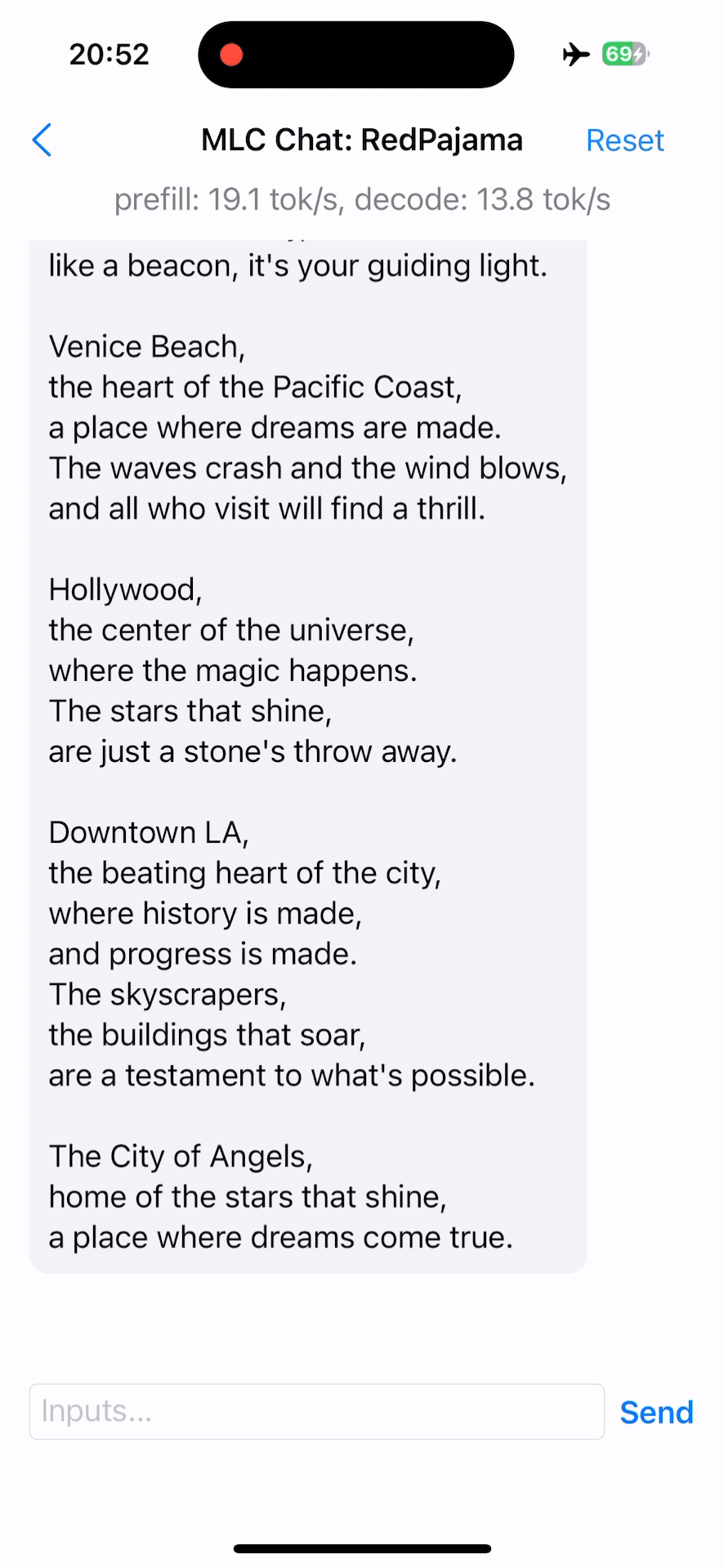
下一步做什么¶
查看 MLC LLM 简介 了解 MLC LLM 中完整工作流程的介绍。
根据您的用例,查看我们的 API 文档和教程页面:
转换模型权重,如果您想运行自己的模型。
编译模型库,如果您想部署到网页/iOS/Android 或控制模型优化。
报告任何问题或提出任何问题:在 GitHub 仓库 中打开新问题。