MLC LLM 简介¶
MLC LLM 是机器学习编译器和高性能部署引擎,专为大型语言模型设计。该项目的使命是让每个人都能在自己的平台上原生地开发、优化和部署 AI 模型。
本页面是快速教程,介绍如何试用 MLC LLM,以及使用 MLC LLM 部署您自己的模型的步骤。
安装¶
MLC LLM 可以通过 pip 安装。建议始终在隔离的 conda 虚拟环境中安装。
要验证安装,请激活您的虚拟环境,然后运行
python -c "import mlc_llm; print(mlc_llm.__path__)"
您应该会看到 MLC LLM Python 包的安装路径。
Chat CLI¶
作为第一个示例,尝试使用 4 位量化的 8B Llama-3 模型在 MLC LLM 中体验聊天 CLI。您可以通过一行命令运行 MLC 聊天:
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
第一次运行此命令可能需要 1-2 分钟。等待后,此命令将启动聊天界面,您可以在其中输入提示并与模型聊天。
You can use the following special commands:
/help print the special commands
/exit quit the cli
/stats print out the latest stats (token/sec)
/reset restart a fresh chat
/set [overrides] override settings in the generation config. For example,
`/set temperature=0.5;max_gen_len=100;stop=end,stop`
Note: Separate stop words in the `stop` option with commas (,).
Multi-line input: Use escape+enter to start a new line.
user: What's the meaning of life
assistant:
What a profound and intriguing question! While there's no one definitive answer, I'd be happy to help you explore some perspectives on the meaning of life.
The concept of the meaning of life has been debated and...
下图展示了此聊天 CLI 命令背后的运行过程。第一次运行该命令时,主要有三个阶段。
阶段 1. 预量化权重下载。此阶段会自动从 Hugging Face 下载预量化的 Llama-3 模型,并将其保存到您的本地缓存目录中。
阶段 2. 模型编译 。此阶段会自动优化 Llama-3 模型,利用 Apache TVM 编译器中的机器学习编译技术加速 GPU 上的模型推理,并生成二进制模型库,使语言模型能够在您的本地 GPU 上执行。
阶段 3. 聊天运行时。 此阶段使用阶段 2 中构建的模型库和阶段 1 中下载的模型权重,启动一个平台原生的聊天运行时来驱动 Llama-3 模型的执行。
在本地缓存了预量化的模型权重和编译后的模型库。因此,阶段 1 和阶段 2 在多次运行中只会执行 一次。

MLC LLM 中的工作流程¶
备注
如果您希望启用张量并行以在多个 GPU 上运行 LLM,请指定参数 --overrides "tensor_parallel_shards=$NGPU"。例如,
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC --overrides "tensor_parallel_shards=2"
Python API¶
在第二个示例中,使用 MLC LLM 的聊天补全 Python API 运行 Llama-3 模型。您可以将以下代码保存到 Python 文件中并运行它。
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC"
engine = MLCEngine(model)
# Run chat completion in OpenAI API.
for response in engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=True,
):
for choice in response.choices:
print(choice.delta.content, end="", flush=True)
print("\n")
engine.terminate()
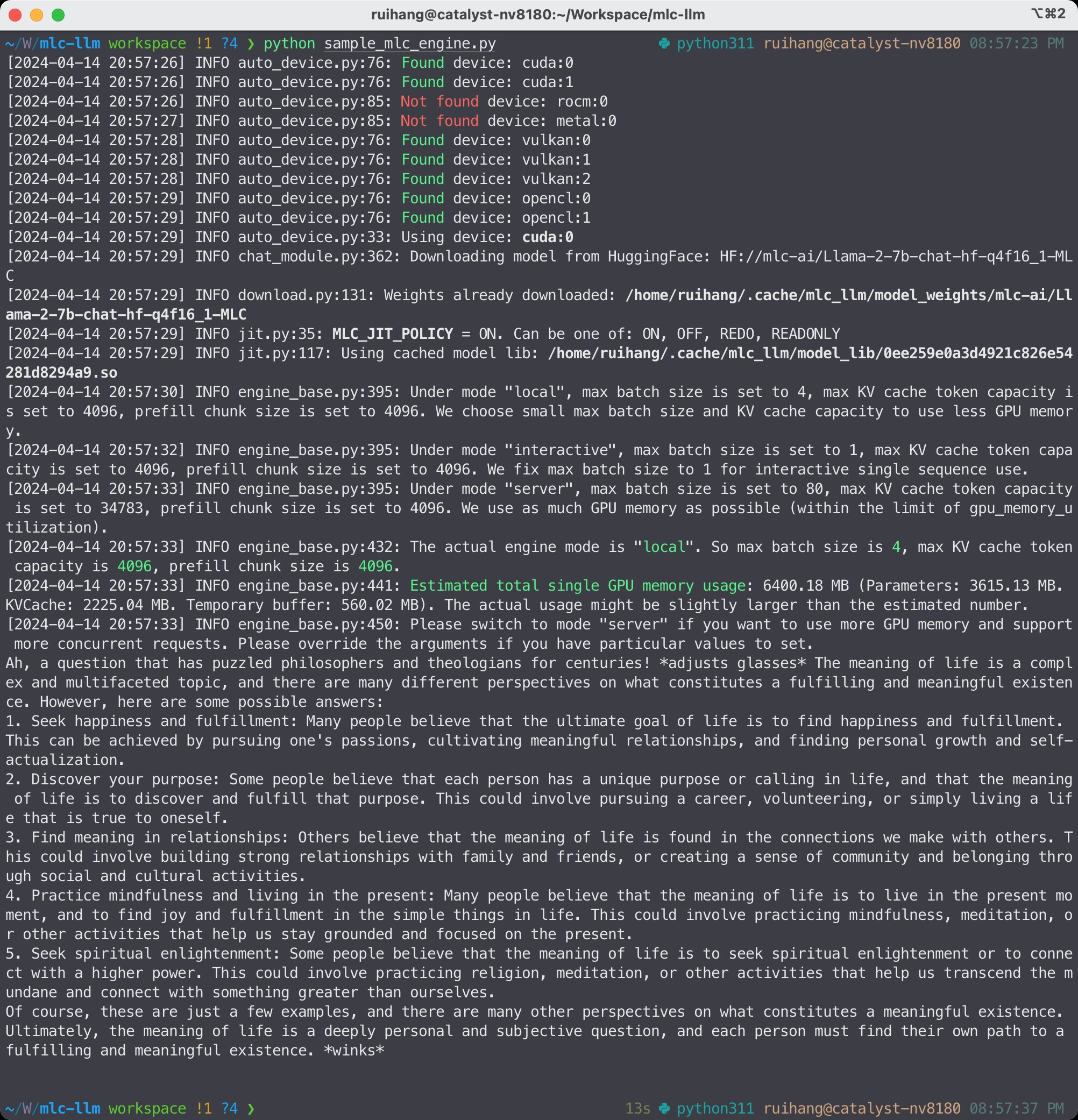
MLC LLM Python API¶
此代码示例首先使用 4 位量化的 Llama-3 模型创建 mlc_llm.MLCEngine 实例。设计的 Python API mlc_llm.MLCEngine 与 OpenAI API 对齐,这意味着您可以以与使用 OpenAI 的 Python 包 相同的方式使用 mlc_llm.MLCEngine 进行同步和异步生成。
在此代码示例中,使用同步聊天补全接口并遍历所有流式响应。如果您希望在不流式传输的情况下运行,可以运行
response = engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the meaning of life?"}],
model=model,
stream=False,
)
print(response)
您还可以尝试 OpenAI 聊天补全 API 中支持的不同参数。如果您希望进行并发异步生成,可以使用 mlc_llm.AsyncMLCEngine。
备注
如果您希望启用张量并行以在多个 GPU 上运行 LLM,请在 MLCEngine 构造函数中指定参数 model_config_overrides。例如,
from mlc_llm import MLCEngine
from mlc_llm.serve.config import EngineConfig
model = "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC"
engine = MLCEngine(
model,
engine_config=EngineConfig(tensor_parallel_shards=2),
)
REST Server¶
对于第三个示例,启动 REST 服务器来为 OpenAI 聊天补全请求提供 4 位量化的 Llama-3 模型。可以通过命令行启动服务器:
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC
服务器默认挂载在 http://127.0.0.1:8000,您可以使用 --host 和 --port 来设置不同的主机和端口。当服务器准备就绪时(显示 INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)),可以打开新的 shell 并通过以下命令发送 cURL 请求:
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"model": "HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC",
"messages": [
{"role": "user", "content": "Hello! Our project is MLC LLM. What is the name of our project?"}
]
}' \
http://127.0.0.1:8000/v1/chat/completions
服务器将处理此请求并返回响应。与 Python API 类似,您可以传递参数 "stream": true 来请求流式响应。
备注
如果您希望启用张量并行以在多个 GPU 上运行 LLM,请指定参数 --overrides "tensor_parallel_shards=$NGPU"。例如,
mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC --overrides "tensor_parallel_shards=2"
部署模型¶
到目前为止,一直在使用从 Hugging Face 预转换的模型权重。本节介绍了关于如何 使用 MLC LLM 运行您自己的模型 的核心工作流程。
以 Phi-2 作为示例模型。假设 Phi-2 模型已下载并放置在 models/phi-2 下,准备您自己的模型主要有两个步骤。
步骤 1. 生成 MLC 配置。 第一步是生成 MLC LLM 的配置文件。
export LOCAL_MODEL_PATH=models/phi-2 # The path where the model resides locally. export MLC_MODEL_PATH=dist/phi-2-MLC/ # The path where to place the model processed by MLC. export QUANTIZATION=q0f16 # The choice of quantization. export CONV_TEMPLATE=phi-2 # The choice of conversation template. mlc_llm gen_config $LOCAL_MODEL_PATH \ --quantization $QUANTIZATION \ --conv-template $CONV_TEMPLATE \ -o $MLC_MODEL_PATH
配置生成命令接收本地模型路径、MLC 输出的目标路径、MLC 中的对话模板名称和 MLC 中的量化名称。这里的量化
q0f16表示没有量化的 float16,对话模板phi-2是 MLC 中 Phi-2 模型的模板。如果您希望在多个 GPU 上启用张量并行,请在配置生成命令中添加参数
--tensor-parallel-shards $NGPU。MLC 中支持的量化完整列表。您可以尝试 MLC LLM 中的不同量化方法。典型的量化方法包括
q4f16_1用于 4 位组量化,q4f16_ft用于 4 位 FasterTransformer 格式量化。
步骤 2. 转换模型权重。 在此步骤中,将模型权重转换为 MLC 格式。
mlc_llm convert_weight $LOCAL_MODEL_PATH \ --quantization $QUANTIZATION \ -o $MLC_MODEL_PATH
此步骤使用原始模型权重并将其转换为 MLC 格式。转换后的权重将存储在
$MLC_MODEL_PATH下,该目录与步骤 1 中生成的配置文件所在的目录相同。
现在,可以尝试使用聊天 CLI 运行您自己的模型:
mlc_llm chat $MLC_MODEL_PATH
第一次运行时,将自动触发模型编译以优化模型以加速 GPU 并生成二进制模型库。模型 JIT 编译完成后将显示聊天界面。您还可以在 Python API、MLC 服务和其他使用场景中使用此模型。
(可选)编译模型库¶
在前面的部分中,模型库在 mlc_llm.MLCEngine 启动时编译,这就是所说的“JIT(即时)模型编译”。在某些情况下,显式编译模型库是有益的。可以通过分发库进行部署,而无需经过编译,从而减少依赖项。它还将启用高级选项,例如为网页和移动部署交叉编译库。
以下是 MLC LLM 中编译模型库的示例命令:
export MODEL_LIB=$MLC_MODEL_PATH/lib.so # ".dylib" for Intel Macs.
# ".dll" for Windows.
# ".wasm" for web.
# ".tar" for iPhone/Android.
mlc_llm compile $MLC_MODEL_PATH -o $MODEL_LIB
在运行时,需要指定此模型库路径以使用它。例如,
# For chat CLI
mlc_llm chat $MLC_MODEL_PATH --model-lib $MODEL_LIB
# For REST server
mlc_llm serve $MLC_MODEL_PATH --model-lib $MODEL_LIB
from mlc_llm import MLCEngine
# For Python API
model = "models/phi-2"
model_lib = "models/phi-2/lib.so"
engine = MLCEngine(model, model_lib=model_lib)
编译模型库 详细介绍了模型编译命令,您可以在其中找到将模型编译到不同硬件后端(例如 WebGPU、iOS 和 Android)的说明和示例命令。
通用部署¶
MLC LLM 是高性能的通用大型语言模型部署解决方案,旨在通过编译器加速实现任何大型语言模型的原生 API 原生部署。到目前为止,已经经历了在本地 GPU 环境中运行的几个示例。该项目支持多种 GPU 后端。
您可以在编译和运行时使用 --device 选项来选择特定的 GPU 后端。例如,如果您有 NVIDIA 或 AMD GPU,您可以尝试使用以下选项通过 vulkan 后端运行聊天。基于 Vulkan 的 LLM 应用程序可以在不太典型的环境中运行(例如 SteamDeck)。
mlc_llm chat HF://mlc-ai/Llama-3-8B-Instruct-q4f16_1-MLC --device vulkan
相同的核心 LLM 运行时引擎为所有后端提供支持,只要模型适合相应硬件后端的内存和计算预算,就可以跨后端部署相同的模型。还利用机器学习编译来构建后端专用优化,以在目标后端上尽可能获得最佳性能,并在我们支持的后端之间重用关键见解和优化。
请查看下面的下一步部分,以了解更多关于不同部署场景的信息,例如基于 WebGPU 的浏览器部署、移动设备和其他设置。
总结和下一步做什么¶
简要总结本页面,
经历了 MLC LLM 的三个示例(聊天 CLI、Python API 和 REST 服务器),
介绍了如何为您自己的模型转换模型权重以使用 MLC LLM 运行,以及(可选)如何编译您的模型。
还讨论了 MLC LLM 的通用部署能力。
接下来,请随时查看以下页面以获取快速入门示例和有关特定平台的更多详细信息
快速入门示例 适用于 Python API、聊天 CLI、REST 服务器、网页浏览器、iOS 和 Android。
根据您的用例,查看我们的 API 文档和教程页面:
将模型权重转换为 MLC 格式,如果您想运行自己的模型。
编译模型库,如果您想部署到网页/iOS/Android 或控制模型优化。
报告任何问题或提出任何问题:在 GitHub 仓库 中打开新问题。