Multi-GPU Training
内容
Multi-GPU Training¶
📚 This guide explains how to properly use multiple GPUs to train a dataset with YOLOv5 🚀 on single or multiple machine(s).
Before You Start¶
Clone this repo and install requirements.txt dependencies, including Python>=3.8 and PyTorch>=1.7.
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
pip install -r requirements.txt
Training¶
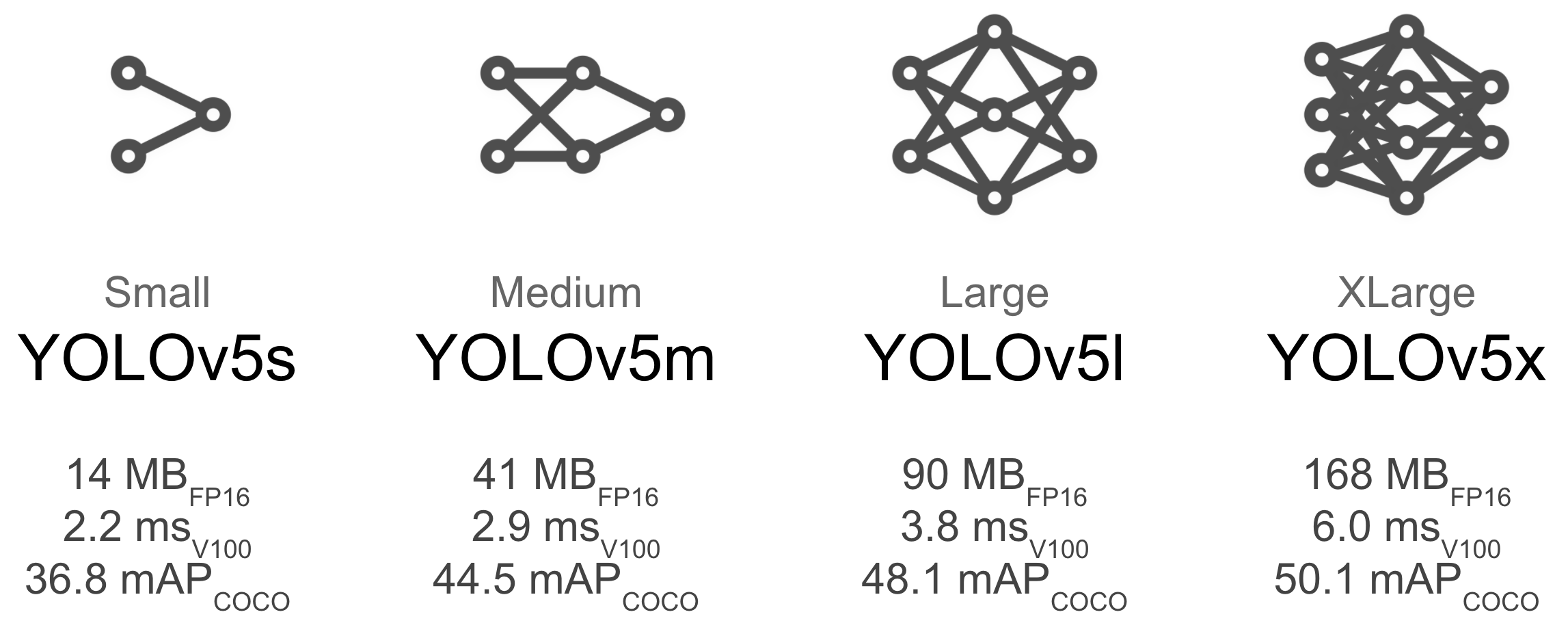
Select a pretrained model to start training from. Here we select YOLOv5l, the smallest model available. See our README table for a full comparison of all models. We will train this model with Multi-GPU on the COCO dataset.
Single GPU¶
$ python train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt --device 0
Multi-GPU DataParallel Mode (⚠️ not recommended)¶
You can increase the device to use Multiple GPUs in DataParallel mode.
$ python train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt --device 0,1
This method is slow and barely speeds up training compared to using just 1 GPU.
Multi-GPU DistributedDataParallel Mode (✅ recommended)¶
You will have to pass python -m torch.distributed.launch --nproc_per_node, followed by the usual arguments.
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt
--nproc_per_node specifies how many GPUs you would like to use. In the example above, it is 2.
--batch-size is now the Total batch-size. It will be divided evenly to each GPU. In the example above, it is 64/2=32 per GPU.
The code above will use GPUs 0... (N-1).
Use specific GPUs (click to expand)
You can do so by simply passing --device followed by your specific GPUs. For example, in the code below, we will use GPUs 2,3.
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 2,3
Use SyncBatchNorm (click to expand)
SyncBatchNorm could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is only available for Multiple GPU DistributedDataParallel training.
It is best used when the batch-size on each GPU is small (<= 8).
To use SyncBatchNorm, simple pass --sync-bn to the command like below,
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn
Use Multiple machines (click to expand)
This is only available for Multiple GPU DistributedDataParallel training.
Before we continue, make sure the files on all machines are the same, dataset, codebase, etc. Afterwards, make sure the machines can communicate to each other.
You will have to choose a master machine(the machine that the others will talk to). Note down its address(master_addr) and choose a port(master_port). I will use master_addr = 192.168.1.1 and master_port = 1234 for the example below.
To use it, you can do as the following,
# On master machine 0
$ python -m torch.distributed.launch --nproc_per_node G --nnodes N --node_rank 0 --master_addr "192.168.1.1" --master_port 1234 train.py --batch-size 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
# On machine R
$ python -m torch.distributed.launch --nproc_per_node G --nnodes N --node_rank R --master_addr "192.168.1.1" --master_port 1234 train.py --batch-size 64 --data coco.yaml --cfg yolov5s.yaml --weights ''
where G is number of GPU per machine, N is the number of machines, and R is the machine number from 0...(N-1).
Let’s say I have two machines with two GPUs each, it would be G = 2 , N = 2, and R = 1 for the above.
Training will not start until all N machines are connected. Output will only be shown on master machine!
Notes¶
This does not work on Windows!
batch-sizemust be a multiple of the number of GPUs!GPU 0 will take more memory than the other GPUs. (Edit: After 1.6 pytorch update, it may take even more memory.)
If you get
RuntimeError: Address already in use, it could be because you are running multiple trainings at a time. To fix this, simply use a different port number by adding--master_portlike below,
$ python -m torch.distributed.launch --master_port 1234 --nproc_per_node 2 ...
Results¶
Tested on COCO2017 dataset using V100s for 3 epochs with yolov5l and averaged.
DistributedDataParallel mode.
Command
$ python train.py --batch-size 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 0
$ python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt
$ python -m torch.distributed.launch --nproc_per_node 4 train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt
$ python -m torch.distributed.launch --nproc_per_node 8 train.py --batch-size 64 --data coco.yaml --weights yolov5s.pt


FAQ¶
If an error occurs, please read the checklist below first! (It could save your time)
Checklist (click to expand)
- Have you properly read this post?
- Have you tried to reclone the codebase? The code changes daily.
- Have you tried to search for your error? Someone may have already encountered it in this repo or in another and have the solution.
- Have you installed all the requirements listed on top (including the correct Python and Pytorch versions)?
- Have you tried in other environments listed in the "Environments" section below?
- Have you tried with another dataset like coco128 or coco2017? It will make it easier to find the root cause.
If you went through all the above, feel free to raise an Issue by giving as much detail as possible following the template.
Environments¶
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Google Colab and Kaggle notebooks with free GPU:


Google Cloud Deep Learning VM. See GCP Quickstart Guide
Amazon Deep Learning AMI. See AWS Quickstart Guide
Docker Image. See Docker Quickstart Guide

Status¶
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
Credits¶
I would like to thank @MagicFrogSJTU, who did all the heavy lifting, and @glenn-jocher for guiding us along the way.